
Why AI visibility now depends less on being retrievable and more on being easy for AI systems to explore, connect, and cite.
For a long time, the logic of AI search seemed straightforward: if your content could be retrieved, it could influence the answer. That model is now beginning to break down.
A growing class of AI systems does not simply pull a few relevant passages and stop there. Instead, it identifies entities, follows relationships, expands into nearby evidence, verifies what it finds, and decides when it has enough support to answer with confidence.
That shift changes what visibility means. It is no longer only about whether your content can be found, but whether an AI system can move through it, connect the right evidence, and trace its answer back to a source it can trust.
This is why knowledge graphs matter more than ever. They are no longer just a structured layer behind your content. They are becoming part of the environment AI explores when similarity alone is not enough.
In our previous blogpost, we showed that structured data alone is not enough to win in AI search, and that turning your knowledge graph into a visible, navigable “memory layer” for AI systems could improve answer accuracy by up to 34%.
In this article, we focus on the practical side of that shift: what has changed in retrieval, why knowledge graphs are becoming search spaces, and what innovation and marketing teams should do now.
Retrieval Is Changing
For most of the history of retrieval-augmented generation, the retrieval step was straightforward: embed the query, pull the most similar chunks from an index, pass them to a language model, and produce an answer. That approach is fast, cheap, and often good enough when the evidence is concentrated in one or two passages.
The problem appears when the answer is spread across multiple documents, entities, or sections of a corpus. In those cases, simply adding more context does not reliably solve the issue, because the model may retrieve passages that resemble the query while still struggling to navigate the structural paths that connect the actual evidence. This is where context rot begins to appear.
This is the gap a new generation of retrieval architectures is designed to close. The shift is from a static top-k model, where a fixed set of chunks is retrieved upfront, to an adaptive exploration model, where the AI proposes follow-up steps, follows entity links, expands neighborhoods, verifies evidence, and decides when it has gathered enough to answer well.
That is a meaningful change. Retrieval is becoming less like a simple lookup and more like a guided investigation.
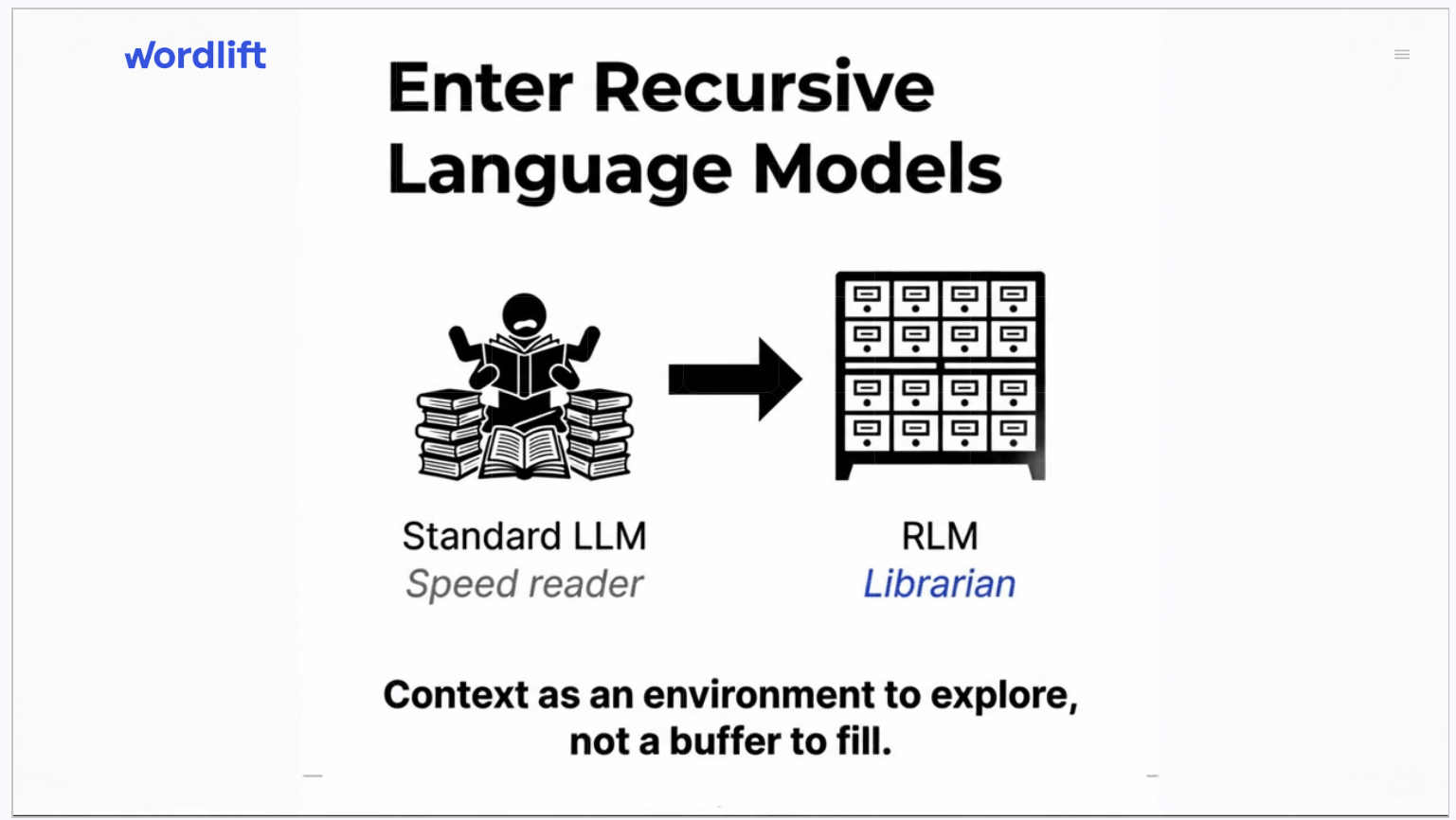
Introducing RLM-on-KG: The AI That Navigates
The research we want to share introduces a system called RLM-on-KG (Recursive Language Model on Knowledge Graph), a retrieval architecture that treats an LLM as an autonomous navigator over an RDF-encoded knowledge graph.
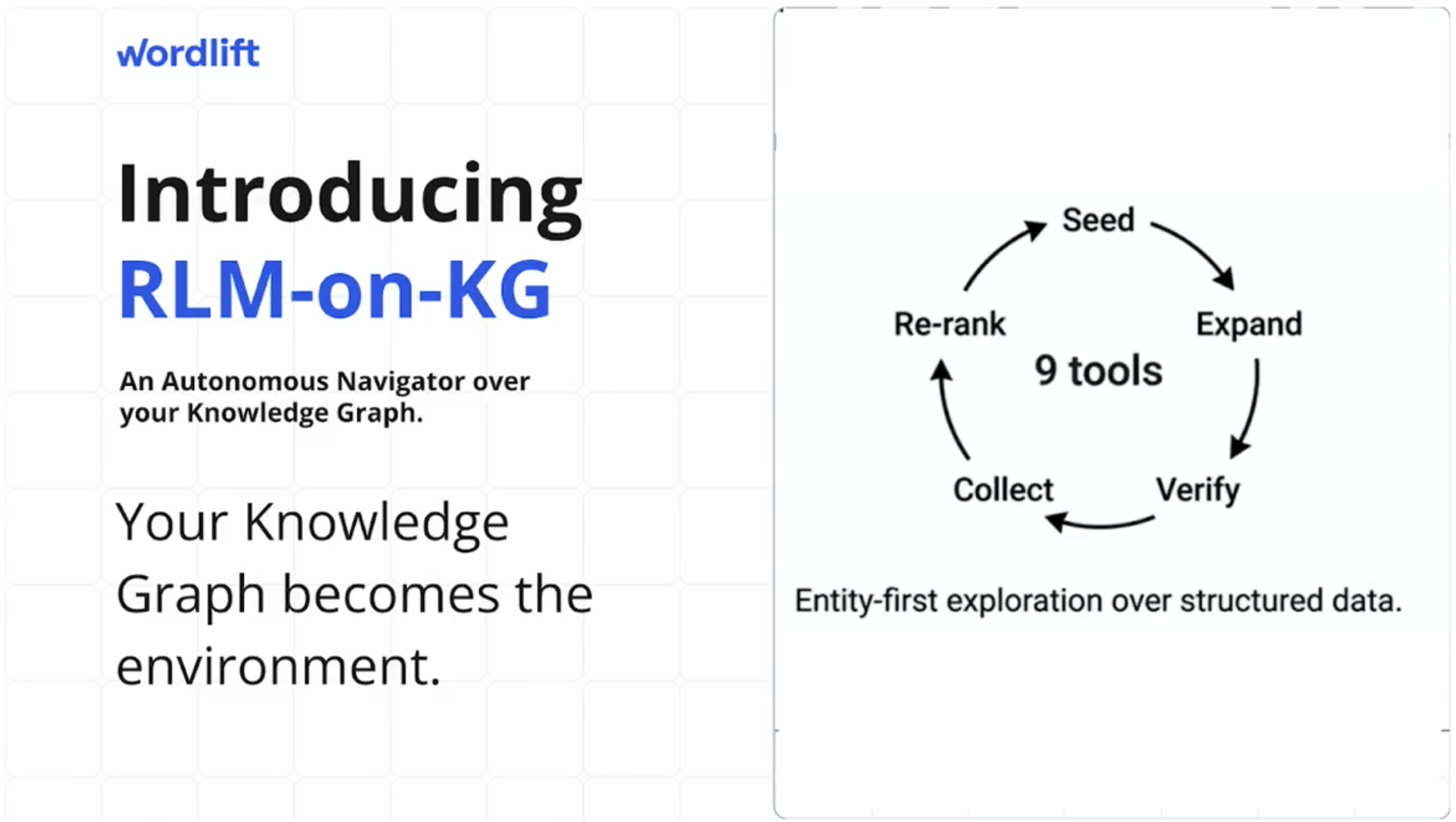
The core idea is simple: instead of asking the AI to retrieve the most similar chunks and stop there, RLM-on-KG gives the model a set of tools and lets it actively explore the knowledge graph at query time to assemble its own evidence.
The exploration unfolds in three phases:
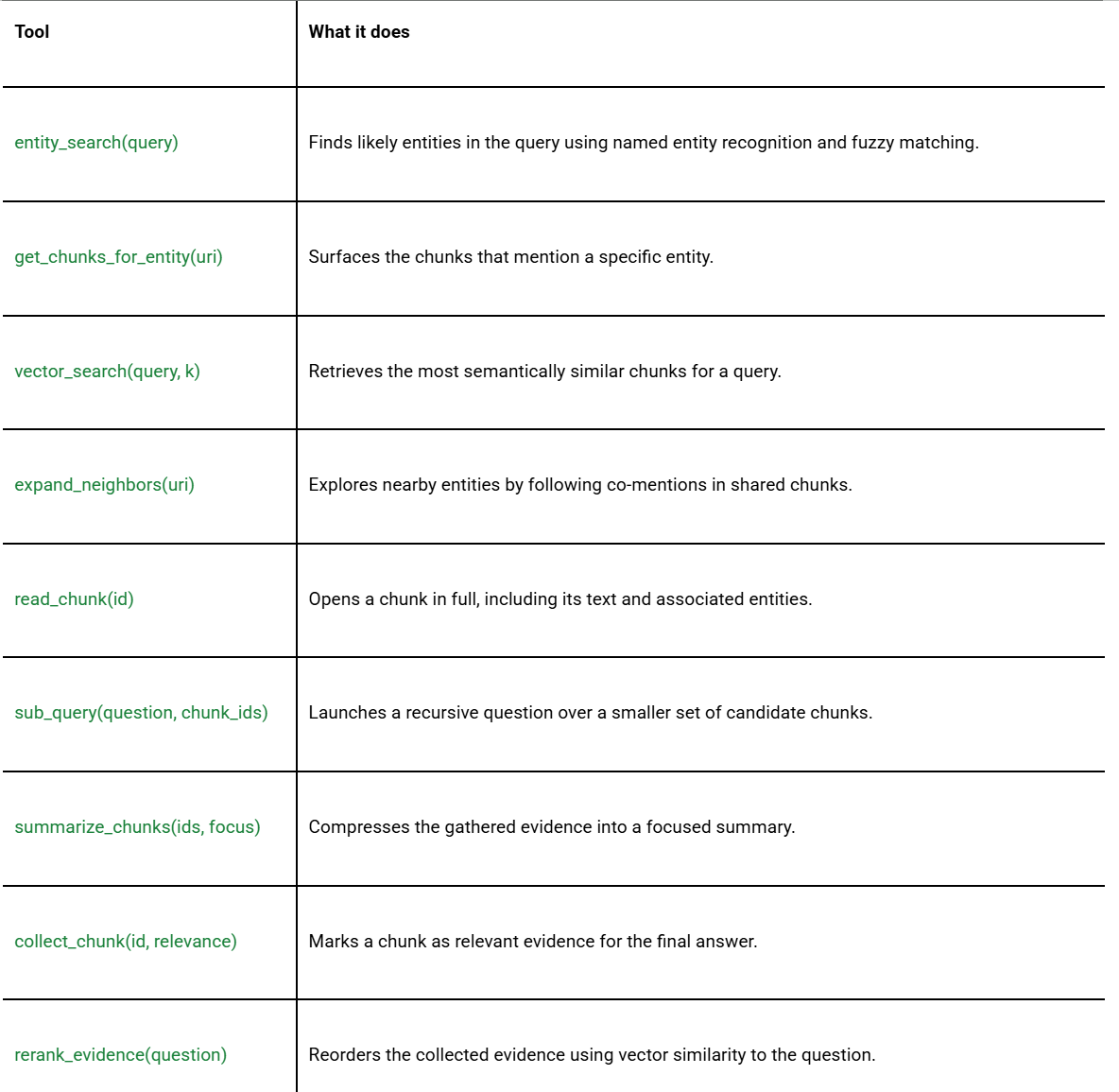
- Entity Discovery: the LLM identifies seed entities in the question and surfaces chunks directly linked to them.
- Graph Expansion: the model expands to co-mentioned entities, then follows those links to uncover additional evidence that vector search alone would likely miss.
- Verification and Extraction: the LLM runs recursive sub-queries to verify facts across chunk clusters, marks relevant evidence, and re-ranks everything before producing an answer.
Unlike GraphRAG-style pipelines, which depend on offline LLM processing such as entity extraction, community detection, and summary generation before the first query can be answered, RLM-on-KG performs its exploration live at query time over a deterministically built mention graph.
This is the architecture of agentic retrieval: an AI that does not just consume your content, but navigates it like an explorer with a map.
That matters because it offers a concrete explanation for a broader market shift. The issue is not simply that models are getting better at language. It is that some retrieval systems are now designed to explore connected knowledge environments rather than passively consume a fixed set of passages.
This is also where the knowledge graph changes its role. It is no longer just a store of entities and metadata. It becomes a navigable space where evidence can be discovered, connected, and attributed.
From Chunk Stuffing to Evidence Foraging
One of the most useful concepts in this research is the distinction between chunk stuffing and evidence foraging.
Traditional RAG retrieves a static top-k set of chunks. The system does not adapt, does not explore, and does not follow links. It stuffs what looks most similar into the context window and hopes the answer is there.
GEO-aligned systems behave differently. They forage. They follow entity handles, expand neighborhoods, refine sub-queries, and accumulate supporting fragments iteratively. They treat the knowledge graph as a landscape to search, not a bucket to sample from.
The benchmark results make this difference visible. When tested on 519 questions across five classic novels, RLM-on-KG showed one clear pattern: it performs best when structure matters most.
For questions where the gold evidence is scattered across 11 or more chunks, the system’s win rate rises to 56%, with a mean improvement of +1.38 F1 points over a strong graph-based baseline. On fact-retrieval questions with highly scattered evidence, the win rate reaches 100%, albeit on a small sample. When the evidence is concentrated in one or two passages, the advantage largely disappears, because in those cases vector similarity is already sufficient.

That is the real takeaway. This system is not always better. It is selectively better, and it performs best in exactly the scenarios that are hardest for traditional retrieval.
Why This Matters for Marketing and Innovation Teams
For marketing teams, this changes the optimization target. It is still important to create relevant content, but relevance alone is no longer enough if the supporting evidence is disconnected, hard to trace, or buried in a structure that AI cannot navigate effectively.
The old model optimized for similarity. The new one optimizes for navigability. In practical terms, that means making evidence reachable through clear entity relationships and preserving the source context that allows an AI system to cite confidently.
For innovation leaders, the implication is broader. A knowledge graph is no longer just an internal data asset or a technical SEO layer. It is becoming an operational environment for AI agents, one that shapes whether those systems can produce answers about your brand that are accurate, complete, and trustworthy.
That matters because AI-generated answers increasingly sit close to the moment of decision. When an AI response becomes one of the first meaningful interactions a customer has with your brand, the quality of that answer becomes a business issue, not just a technical detail.
What to Improve Now
The research points to a set of concrete levers that influence how well content supports agent-driven retrieval. These are not abstract theory points. They are the building blocks of navigability.
- Stable entity URIs, so AI agents can reliably resolve and revisit the same entities across sessions.
- Explicit mention links between entities and content chunks, so there are real paths through the graph rather than isolated references.
- Provenance anchors linking chunks back to source documents, so evidence can be attributed and cited.
- Dereferenceable entity pages with machine-readable descriptions, so agents can read useful context when they arrive at a node.
- Stable chunk anchors, so systems can return to the same evidence even after re-indexing.
- Crawlable endpoints or structured feeds, so agents can access entity and chunk data directly.
- Clean entity boundaries, including consistent naming and alias resolution, so systems can tell when different references point to the same thing.
Our work also identifies three measurement ideas that matter in this environment:
- Attribution depth: What fraction of the final evidence was not in the initial vector top-k, but discovered through graph traversal? This measures how much your structural links contribute beyond similarity search.
- Path efficiency: How much relevant evidence does an agent collect per tool call? This reflects how well your entity relationships guide exploration.
- Citation readiness: What proportion of final evidence chunks have stable identifiers linking entity, chunk, and document? This determines whether an AI agent can confidently cite your content.
This matters because it moves the conversation beyond vague ideas about AI visibility. It gives teams a more concrete way to think about performance in terms of discoverability, reachability, and attribution quality.
There is another important benefit here as well. Each time a system like RLM-on-KG explores a question, it leaves behind a trace showing which entities were found, which neighborhoods were expanded, which chunks were collected, and where the process stalled or fell back to vector search.
Those traces can become a diagnostic tool for the knowledge graph itself. They can reveal missing entities, weak connectivity, provenance problems, and repeated query bottlenecks. That means the graph becomes not only a retrieval layer, but also a quality mirror that shows where your knowledge architecture needs improvement.
What Comes Next
The research behind these findings, RLM-on-KG: LLM-Driven Recursive Exploration of Knowledge Graphs for Grounded Question Answering, is currently under peer review. The findings presented here are rigorous and reproducible, and the code and data are publicly available at github.com/wordlift/rlm-on-kg while the formal paper moves through the review process.
Even so, the directional lesson is already clear. The next phase of AI visibility will not be won only by content that exists or by content that happens to match a prompt well. It will be shaped by how easily AI systems can move through your knowledge, connect the right evidence, and cite it with confidence.
That is why the conversation is shifting from retrievability to navigability. It is also why knowledge graphs are becoming more strategic in AI search, not less.
If your team is working on AI visibility, enterprise knowledge architecture, or content strategy, the priorities are already visible. Audit whether your most important entities are findable. Strengthen the links between entities and the content that mentions them. Stabilize your identifiers. Add provenance to your chunks. Make your knowledge easier for AI to navigate, not just easier to index.
That is the real shift. A knowledge graph is no longer just a structured layer beneath your content. It is becoming part of the reasoning surface AI uses to understand your business.

Move beyond retrievability. Master navigability.
The shift to RLM-on-KG and agentic retrieval is changing the ROI of SEO. If you’re ready to transition from a static website to an operational environment for AI agents, we’re ready to show you the way. Book a call with our team and ensure your business is not just found, but explored.