
Building a Knowledge Graph is phase one. Governing it is the critical control layer that keeps every AI endpoint—from search overviews and customer-facing chatbots to corporate copilots and autonomous agents—telling the truth about your brand. Whether you are a Fortune 500 company managing vast data lakes or a growing e-commerce business running on a CMS, keeping your brand’s machine-readable facts true is the defining digital responsibility of the synthetic content era.
Your Brand Now Speaks Through Machines You Do Not Fully Control
Five years ago, your brand spoke through channels you owned and controlled: your website, your marketing campaigns, and your designated spokespeople. Today, your brand also speaks through Google’s AI Overviews, local conversational search engines, customer-service chatbots, internal corporate copilots, and a rising layer of autonomous agents that retrieve information and transact on your behalf.
Each of these is a digital mouth. Each can confidently state a price, explain a return policy, cite a product specification, or declare a fact about your leadership. And each represents a point of failure where a fact about your brand can be quietly invented.
The natural reflex of business leaders is to ask how to make the underlying AI model more accurate. That is the wrong lever. Hallucination is not a temporary software bug awaiting a patch; under current transformer and large language model (LLM) architectures, it is an inherent structural property of how these systems produce text. You cannot govern the model. You can only govern what the model is permitted to treat as true.
This is where Knowledge Graph governance becomes essential. If a Knowledge Graph is your corporate memory—the structured, machine-readable record of what your organization actually knows—then governance is what makes that memory authoritative, consistent, and legally defensible. It is the difference between owning a library and running one with a dedicated librarian, a catalog, and a returns policy. This discipline begins the moment the graph is built, and it is fast becoming the most strategic data responsibility for both global enterprises and small-to-medium-sized businesses (SMEs).
SECTION 1: The High Stakes of AI Hallucinations on Brand Reputation
A hallucination is a confident, fluent, and highly plausible statement that happens to be completely false. The unique danger of generative AI is not that it is sometimes wrong—it is that AI is most persuasive precisely when it is incorrect.
MIT researchers have found that LLMs generate answers with higher statistical confidence and more assertive language when they are fabricating information than when they are stating verified, retrieved facts. The outputs you should trust the least are frequently dressed in the language you are most inclined to believe.
At scale, the cost of these fabricated statements is no longer abstract or minor:

Knowledge workers now spend an average of more than four hours every week verifying AI outputs (Microsoft), and roughly 40% of customer-service bots have been pulled back or heavily reworked after high-profile hallucination failures.
For a CDO, Compliance Officer, or SME Founder, the legal and reputational figures are the most alarming: when a machine speaks for your brand and gets it wrong, your brand owns the consequences.
The Legal Precedents Are Already Set
1. The Small-to-Medium Business Liability (Moffatt v. Air Canada):
In this landmark case, a British Columbia tribunal held Air Canada liable for incorrect, hallucinated fare information provided to a customer by its chatbot.
Air Canada argued that the chatbot was a separate legal entity responsible for its own statements. The tribunal rejected this defense entirely, establishing the legal precedent that a company is responsible for all information presented on its platforms, whether it originates from a static web page or a probabilistic bot.
For an SME, a similar chatbot hallucination regarding shipping policies, refund windows, or pricing can lead directly to consumer protection lawsuits and immediate margin depletion.
2. The Enterprise Integrity Warning (Deloitte Australia):
In October 2025, Deloitte Australia was forced to refund a portion of a high-value government contract after a report it delivered was discovered to contain fabricated citations and an invented court quotation generated by an AI tool.
The primary lesson drawn by auditors was clear: the model itself was not the fundamental failure; the architecture was. There was no automated provenance check or validation gate between what the generative model produced and what was officially published.
3. The Personal Brand & Local Reputation Cost:
Reputational damage propagates instantly. When an AI search summary recently mislabeled a Canadian musician with a false criminal description—caused by the model confusing two individuals with the same name—it resulted in a canceled performance and real-world safety concerns before any correction could be issued.
Whether you are a local business owner or a global corporation, a fabricated fact surfaced confidently and repeated at scale by AI search engines becomes your brand’s problem the moment it is published. You cannot patch your way to truth; you can only govern the source the machine is allowed to draw from.
SECTION 2: Moving from “Building” to “Governing” Your Knowledge Graph
Most organizations that invest in structured data or a Knowledge Graph treat the project as a one-time construction task. Entities are extracted, connected to public reference points like Wikidata, enriched with Schema.org markup, and compiled into a graph. The graph is deployed, the project is marked complete, and the asset is considered finished.
This is a fundamental misconception. A Knowledge Graph is not a static deliverable; it is a living, breathing model of a moving business.
Prices shift, leadership changes, store hours adjust, product specifications evolve, return windows are modified, and regional compliance certificates are updated. These changes happen weekly, often across siloed systems that never communicate with one another.
An unguarded, static graph quickly drifts away from reality, and every downstream AI endpoint reading from it inherits that drift. Building the graph gives you a memory; governance is what keeps that memory true.
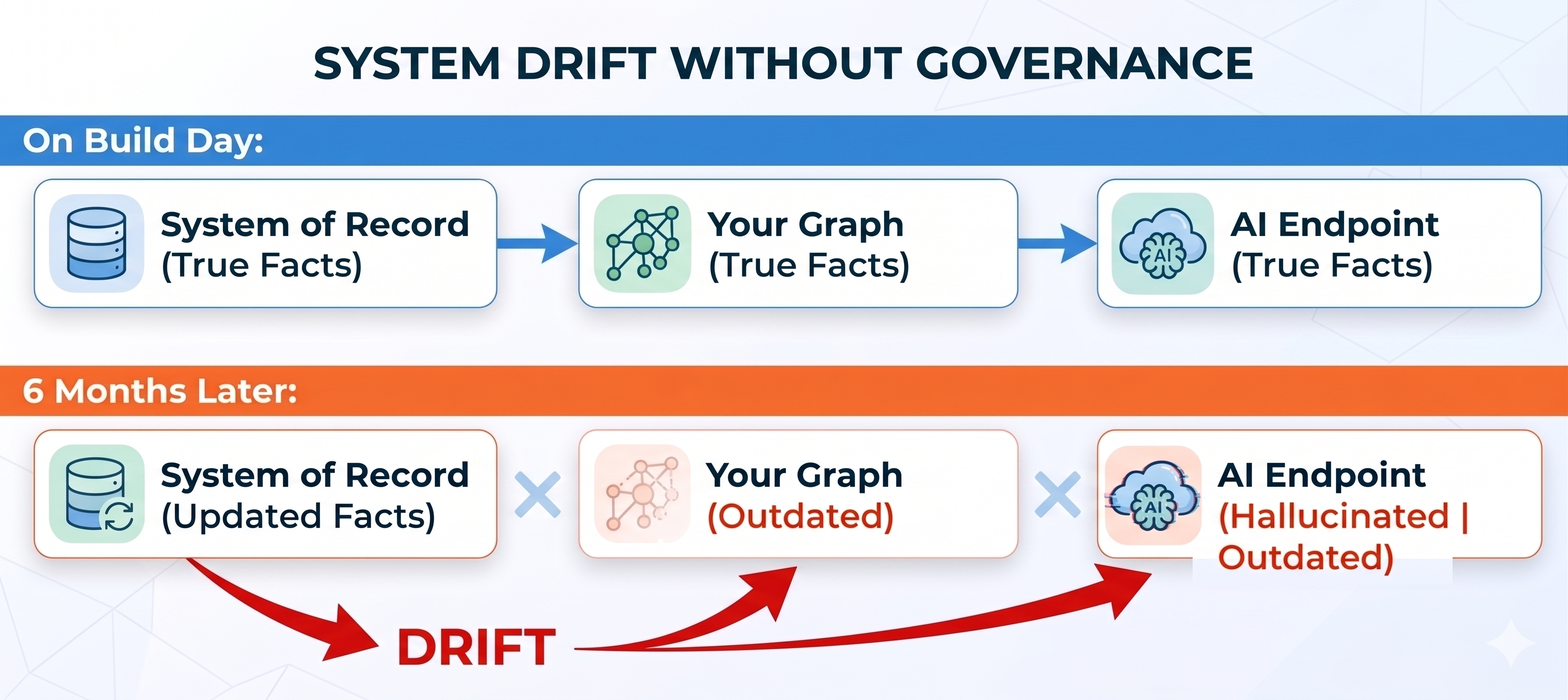
Knowledge Graph governance is the continuous discipline of defining who can assert a fact, how facts are validated before entering the graph, how system conflicts are resolved, how provenance is tracked, and how downstream AI surfaces are forced to ground themselves in the graph rather than guess.
The Governance Spectrum: Enterprise vs. SME
The operational scale of governance depends on your organization’s resources, but the core objective remains the same:
Where WordLift Fits
WordLift acts as the intelligent orchestration and governance layer for this journey:
- For the Enterprise: The WordLift Intelligence Service operates as a centralized semantic controller. It integrates with your existing corporate systems of record—CRM, Product Information Management (PIM), content management systems, and Merchant Centers—and continuously reconciles them into one governed, private Knowledge Graph.
- For the SME: WordLift’s plug-and-play integrations (for Shopify, WordPress, and WooCommerce) automate this complex data engineering. It translates your product catalogs, local service areas, and company facts into a pristine, structured Knowledge Graph with zero manual code, giving smaller businesses the exact same semantic accuracy and AI-defense capabilities as a global enterprise.
SECTION 3: Fact-Checking AI Overviews and Google’s AI Mode
Long before a prospect or customer ever clicks onto your official website, an AI Overview or Google’s conversational AI Mode has often already answered for you. That answer is compiled from the open web—and the open web is a notoriously unreliable narrator of your brand.
An extensive analysis of search engine AI summaries revealed that AI Overviews are accurate roughly 91% of the time. At the scale of several trillion searches a year, that remaining 9% error margin translates into tens of millions of incorrect, hallucinated answers every single hour. Furthermore, over half of the “accurate” answers were ungrounded, linking to source pages that did not actually support the generated claims, with scraper sites and outdated directories frequently ranking among the top-cited sources.
For any brand, three core failure modes occur repeatedly on AI search surfaces:
1. Outdated First-Party Content: A blog post or PDF specification sheet from 2018 is read by the LLM as your current corporate policy, leading to incorrect pricing or product capabilities being presented in search.
2. Third-Party Noise and Scraping: Stale news articles, competitor comparison pages, and spammy scraper sites introduce false attributes that the AI engine synthesizes into its brand overview.
3. Low Machine Readability: Crucial business facts (such as refund policies, B2B services, or leadership) buried in beautiful narrative prose are difficult for a crawler to extract cleanly, forcing the AI model to guess the underlying details.
The correct governance response is not to try and plead with search engine crawlers. It is to publish a highly structured, unambiguous, machine-readable account of your brand—your organization details, your active leadership, your exact product schemas, and your current regional policies—anchored in your Knowledge Graph and exposed via Schema.org structured data.
When your Knowledge Graph is the clearest, most structured, and most authoritative data source available on the web, you shift search engines from guessing about your brand to grounding against your brand. Fact-checking AI Overviews then ceases to be a reactive, one-off SEO firefighting exercise and becomes a structured, continuous governance function.
The brands represented accurately by AI search engines are not the loudest. They are the best governed.
SECTION 4: Implementing Data Validation Loops in Agentic Workflows
As the web shifts from conversational search to agentic workflows, the stakes of data accuracy escalate dramatically. A standard chatbot simply answers a customer query; an autonomous agent takes a sequence of actions, making decisions and chaining API calls to execute complex tasks. Gartner projects that agentic AI will grow from a tiny fraction of enterprise application software revenue today to roughly one-third within the next decade.
In a chained, multi-step agentic workflow, a single unverified, hallucinated fact does not just produce a single wrong sentence. It propagates and compounds through every subsequent step of the loop, eventually manifesting as an incorrect contract, an illegal shipment, an unauthorized discount, or a regulatory violation.
The Deloitte Australia failure is the textbook architectural warning: there was no validation checkpoint between the generation engine and the output delivery. The modern solution requires an architectural change: a governed agentic workflow must run every brand-critical assertion through a validation loop before allowing the agent to act on it.
SECTION 5: Building a Single Source of Truth for Synthetic Compliance
The most common symptom of an ungoverned AI strategy is highly visible: your public website chatbot says one thing, your Google AI Overview says another, your sales team’s internal copilot drafts a third version, and your voice assistant gives a fourth.
Because each AI endpoint was connected to a different static document or training run, they tell conflicting stories about your brand. Customers notice immediately. Regulators will, too.
A centralized Knowledge Graph resolves this fragmented communication through clean, structured architecture:

When you update a single business entity, a product price, or a regional policy in your Knowledge Graph, that update propagates and enforces itself across every digital surface speaking for your brand. Consistency ceases to be an ongoing manual coordination problem and becomes an inherent property of your technology system.
The Regulatory Imperative: The EU AI Act
For Compliance Officers and Business Owners alike, Knowledge Graph governance is rapidly transforming from a technical optimization into a critical regulatory asset:
- Article 50 Transparency Obligations (Effective 2 August 2026):
The European Union AI Act strictly mandates that synthetic, AI-generated content must be clearly machine-readable as AI-generated, and that robust data provenance must be preserved across its entire lifecycle.
A governed Knowledge Graph provides exactly what this regulatory framework demands: an immutable, dated, and source-attributed record of every brand fact.
- Data Residency and Privacy Controls:
Keeping proprietary business details out of public LLM training sets is a high-priority concern for both enterprises and growing SMEs.
By grounding your AI systems in a private, secure Knowledge Graph, you ensure your competitive intelligence and proprietary customer policies remain within your operational boundary, rather than becoming public fodder for commercial AI models.
The Governance Layer, in One Line
WordLift connects your systems of record, reconciles them into a single governed Knowledge Graph, and delivers verified, provenance-backed facts to every AI surface representing your brand. It is the single, trustworthy memory your machines check before they open their mouths.
Govern Your Corporate Memory Today
Do not wait for your AI endpoints to hallucinate another customer response or misrepresent your brand in search. Ground your AI strategy in a single, governed source of truth.