
Perplexity’s latest research on their pplx-embed model confirms a key aspect in AI visibility:
Citations start with retrieval.
This article is not a catalogue of hacks.
The SEO industry is currently experiencing a surge of misinformation and category errors as concepts from Information Retrieval and NLP get reinterpreted as simplistic “levers” for visibility. Dawn Anderson’s recent deep-dive is a helpful reality check: chunking, for example, is a preprocessing mechanism used by systems, not a ranking metric, and attempts to manually “chunk for bots” can quickly drift into short-term tactics that degrade user experience and age poorly as systems evolve.
Our goal here is more precise:
- to explain how modern embedding stacks are evolving across Perplexity, Google’s ecosystem, and OpenAI
- to clarify what is reasonably inferable vs what is unknowable from the outside
- and to translate the engineering reality into durable content generation requirements that keep content useful for humans while remaining legible to machines
In many grounded-answer pipelines, retrieval is also iterative. The model (or an orchestrator around it) can draft a hypothesis and then retrieve sources to support, verify, and refine that answer. Retrieval is often used to ground and validate, not simply to decide what to say from scratch.
On the open web, the classic index still matters: crawling, canonicalization, lexical indexing, link and quality signals. Only after that do systems select candidate documents and passages for grounding and synthesis.
Within that retrieval stage, embeddings have become a dominant mechanism, but rarely the only one. Google, for example, supports hybrid retrieval patterns that combine token-based retrieval with dense embeddings, followed by reranking.
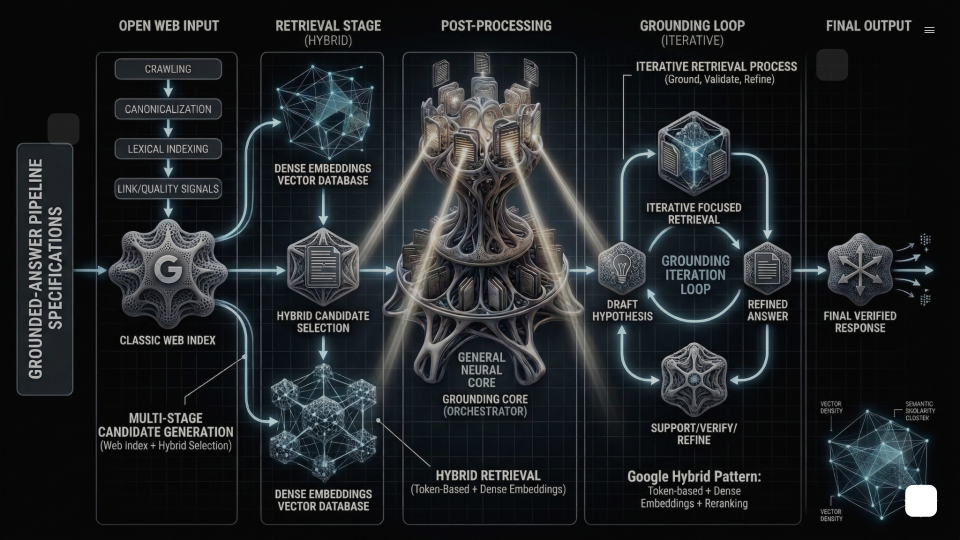
Perplexity’s article focuses on the embedding layer because that is what they are releasing. They describe embeddings as the first stage of their retrieval pipeline for selecting candidates at web scale, before downstream rankers and language models.
If you care about visibility in Perplexity, ChatGPT, Gemini, or any AI-mediated search experience, these shifts increasingly influence how content is structured, organized, and expressed so that it remains both useful to people and legible to machine retrieval systems. Let’s unpack what is happening under the hood across these three ecosystems and what it means for SEO, GEO, and the emerging Reasoning Web.
The hidden gatekeeper: retrieval-first citations
Perplexity makes one thing very clear: in their architecture, embeddings are used at the first stage of candidate selection for web-scale retrieval, determining which documents from billions of pages get considered by downstream rankers and language models.
Google and OpenAI rely on similar multistage patterns, but the key nuance is that retrieval is often hybrid:
- Lexical candidate generation (classic indexing, token-based retrieval such as keyword/BM25-style signals)
- Dense retrieval (embeddings for semantic recall)
- Reranking (more precise models score the candidates)
- Synthesis + citation (the LLM reads the top passages and attributes claims)
This has a profound implication. If your content is not retrieved into the candidate set, it cannot be cited.
Traditional SEO often jumps directly to ranking algorithms or answer generation. In AI search, the upstream bottleneck is: making sure your passages are eligible and competitive in the candidate generation and reranking stages.
To do that, we need to understand what these systems optimize for, and how that translates into content generation requirements.
The 3 Technical Shifts Reshaping Retrieval
To understand how to write for AI, we must decode how Google, OpenAI, and Perplexity map the internet into vector space. Their latest technical documentation reveals three distinct paradigm shifts.
1. Perplexity: Bidirectional Semantics and Late Chunking
Perplexity critiques standard decoder-only embedding approaches because causal masking limits true understanding. Their approach introduces bidirectional context through diffusion-based continued pretraining. Furthermore, their research highlights support for “late chunking,” introducing a contextual embedding model that represents passages with an awareness of the full document.
They also explicitly tune for messy real-world search, long-tail queries, noisy documents, and distribution shifts, rather than clean academic benchmarks.
The translation for marketers: Your page is now a semantic field. Local clarity still matters, but global topical coherence shapes retrieval. Mixed-intent pages or loosely connected sections risk diluting the contextual signal injected into each chunk. Additionally, vague references like "this approach" become mathematically weaker at the passage level. The retriever wants absolute semantic clarity inside the chunk.
2. Google: Task-Aware Asymmetry and Passage Ranking
Google’s transition from lexical search to neural retrieval has evolved from RankBrain to BERT, MUM, and now Gemini-era AI systems. However, an important clarification is required.
Google does not publicly disclose the exact embedding model names used inside the live Google Search ranking stack. What Google does confirm is the use of AI-driven ranking systems and passage-level understanding in Search.
Separately, Google’s Vertex AI and Gemini developer platforms expose production embedding models such as text-embedding-004 and the text-embedding-* family for retrieval and RAG use cases. These models illustrate the design direction of Google’s modern embedding stack, but they should not be assumed to be identical to the internal Search infrastructure.
Two core mechanics nevertheless shape how Google retrieves and evaluates content:
- Passage Ranking via BERT and successors: Google Search evaluates text at the passage level. A highly relevant paragraph buried deep on a disorganized page can independently trigger retrieval.
- Task-Specific Embeddings (developer-facing): In Vertex AI, developers define a
task_type. When embedding web pages, the system designates the text asRETRIEVAL_DOCUMENT, while user queries are designated asRETRIEVAL_QUERY.
The translation for marketers: Google clearly operates with passage-level and task-aware semantic retrieval principles. The vector space is asymmetric. The retriever is mathematically trained to look for text that behaves structurally and semantically like an answer. Content that excessively mirrors query phrasing risks behaving more like a
RETRIEVAL_QUERYthan an authoritativeRETRIEVAL_DOCUMENT, reducing retrieval competitiveness.
3. OpenAI: Matryoshka Representation Learning (MRL) (MRL)
OpenAI’s text-embedding-3-small and text-embedding-3-large models run the retrieval layer for ChatGPT. Their biggest technical breakthrough is the use of Matryoshka Representation Learning (MRL).
MRL allows an embedding vector (for example, up to 3,072 dimensions) to be truncated to a much smaller size (for example, 256 dimensions) without losing its core concept. Like Russian nesting dolls, the most critical, broad semantic information is mathematically front-loaded into the very first dimensions of the vector. The deeper dimensions contain hyper-specific nuances.
The translation for marketers: To save compute costs during massive web-scale searches, AI systems perform coarse-to-fine retrieval, using highly truncated vectors for the first rapid sweep before reranking. Because of MRL, the inverted pyramid of writing is now mathematically reinforced. If you bury the core thesis of your section in the fourth paragraph, it may be truncated out of the semantic vector space during fast retrieval.
The New Writing Model for AI Citation
When you connect the dots, Perplexity’s context-aware chunks, Google’s RETRIEVAL_DOCUMENT tasks, and OpenAI’s Matryoshka dimensions, a clear pattern emerges.
Content that gets cited tends to have passages that are semantically explicit, self-contained, entity-grounded, evidence-backed, and topically coherent at the document level.
This is exactly where solid foundations in traditional SEO bring value and where GEO hype can fall short.
The Matryoshka Paragraph: Lead with the answer
Retrieval and citation systems reward passages that resolve intent quickly. Because OpenAI front-loads meaning into early vector dimensions, you cannot afford warm-up paragraphs.
The fix: Move the key statement to the top. The first sentence should be a direct answer or entity declaration. The second sentence provides scope or definition. Supporting bullets or evidence follow.
Example: How most SEO content fails retrieval
Weak (query-mirroring style):
What is GS1 Digital Link?
GS1 Digital Link is becoming increasingly important in the modern digital ecosystem. In this article, we will explore how it works and why it matters.
Why this underperforms:
- mimics a query vector
- delays the answer
- low early semantic density
- weak entity grounding
Strong (retrieval-optimized):
GS1 Digital Link is a standards-based URI that connects physical products to structured web data and digital experiences. The GS1 Digital Link standard enables AI systems and applications to resolve product identifiers such as GTIN into machine-readable product knowledge.
Why this wins:
- answer in sentence one
- entity fully grounded
- high early semantic density
- behaves like a RETRIEVAL_DOCUMENT
Embody the RETRIEVAL_DOCUMENT
Google expects a retrieved chunk to act as an authoritative answer, not a mirrored search prompt.
The fix: Stop writing headings and opening sentences that simply repeat the user’s query. Eliminate rhetorical questions in body text. AI models are looking for declarative, factual statements that resolve intent, not echoed questions. Let the user ask the question. Your content must be the indisputable answer.
Write chunk-complete, zero-pronoun sections
Because of Google’s passage ranking and Perplexity’s chunk-level retrieval, each section must be able to stand on its own in a vacuum. Assume every paragraph might be extracted independently.
The fix: Avoid sections that only make sense if the reader has processed the entire page. Eliminate floating pronouns (it, they, this process) across paragraph breaks. Reintroduce canonical entities frequently so the retriever captures the exact subject.
Keep entity naming consistent and tighten topical focus
Dense retrieval thrives on semantic clarity. Because Perplexity and Google inject global document-level context into local chunk embeddings, topical dilution is incredibly dangerous.
The fix: Have one primary intent and one dominant entity cluster per page. Introduce the canonical name early, provide common variants once, and avoid drifting terminology. In the Reasoning Web, explicit entities are the anchors that stabilize meaning across systems.
Add verifiable citation triggers
Retrieval gets you into the candidate set. Trust gets you cited.
The fix: Embed concrete numbers, exact dates, named industry standards, primary sources, and official documentation directly into your passages.
Why this matters: Once an LLM reviews retrieved candidates, it favors passages that contain grounded, verifiable data to reduce hallucination risk. In AI search, verifiability increasingly acts as a synthesis signal.
These architectural shifts do not mean that content should suddenly be written for machines instead of people. The web still works because humans read, evaluate, and trust information.
However, there is a practical reality: increasingly, machines are the first readers of our content. Retrieval systems decide which passages are surfaced, synthesized, or cited before a human ever clicks a link.
That creates a subtle but important constraint. Content still needs to be useful and readable for people, but it also needs to be legible to retrieval systems.
The challenge is not to “optimize for embeddings.” It is to structure information so that both humans and machines can understand it clearly.
In practice, this usually means a few simple structural habits that many strong SEO teams already follow.
At the paragraph level
- Start sections with a clear statement or definition
- Name the main entity explicitly rather than relying on pronouns
- Include concrete facts, constraints, or examples where relevant
These practices help readers orient themselves quickly, and they also make passages easier for retrieval systems to interpret.
At the page level
- Maintain a clear primary topic or entity for the page
- Avoid mixing unrelated intents in the same document
- Use consistent terminology when referring to the same concept
These habits improve topical clarity for users and reduce ambiguity for retrieval systems.
Across a content corpus
- Maintain clear canonical entities (often supported by a knowledge graph)
- Avoid publishing multiple pages that say essentially the same thing
- Expand coverage intentionally rather than producing large volumes of near-duplicate content
These are not new SEO ideas. They are simply becoming more important as AI systems rely more heavily on structured signals and semantic retrieval.
A balance worth keeping
There is also an ethical dimension to acknowledge.
If content becomes overly optimized for machine interpretation, it risks becoming formulaic, repetitive, or manipulative. On the other hand, ignoring how retrieval systems work would mean ignoring how information is actually discovered in modern search.
The goal is balance: content that remains genuinely useful for humans while being structured clearly enough for machines to understand and retrieve.
In many ways, this is simply an extension of long-standing SEO best practices. Clear structure, explicit entities, factual grounding, and coherent topics have always improved content quality.
AI retrieval systems are simply making those qualities easier to detect.
Correlating with ChatGPT Citation Research
Kevin Indig recently published a large-scale analysis of how ChatGPT cites sources (here is Kevin’s article on “The Science of how AI pays attention“. His core finding is a strong positional and structural bias: a large share of citations come from the early portion of a page, and citations correlate with passages that are definition-heavy, entity-dense, and factual.
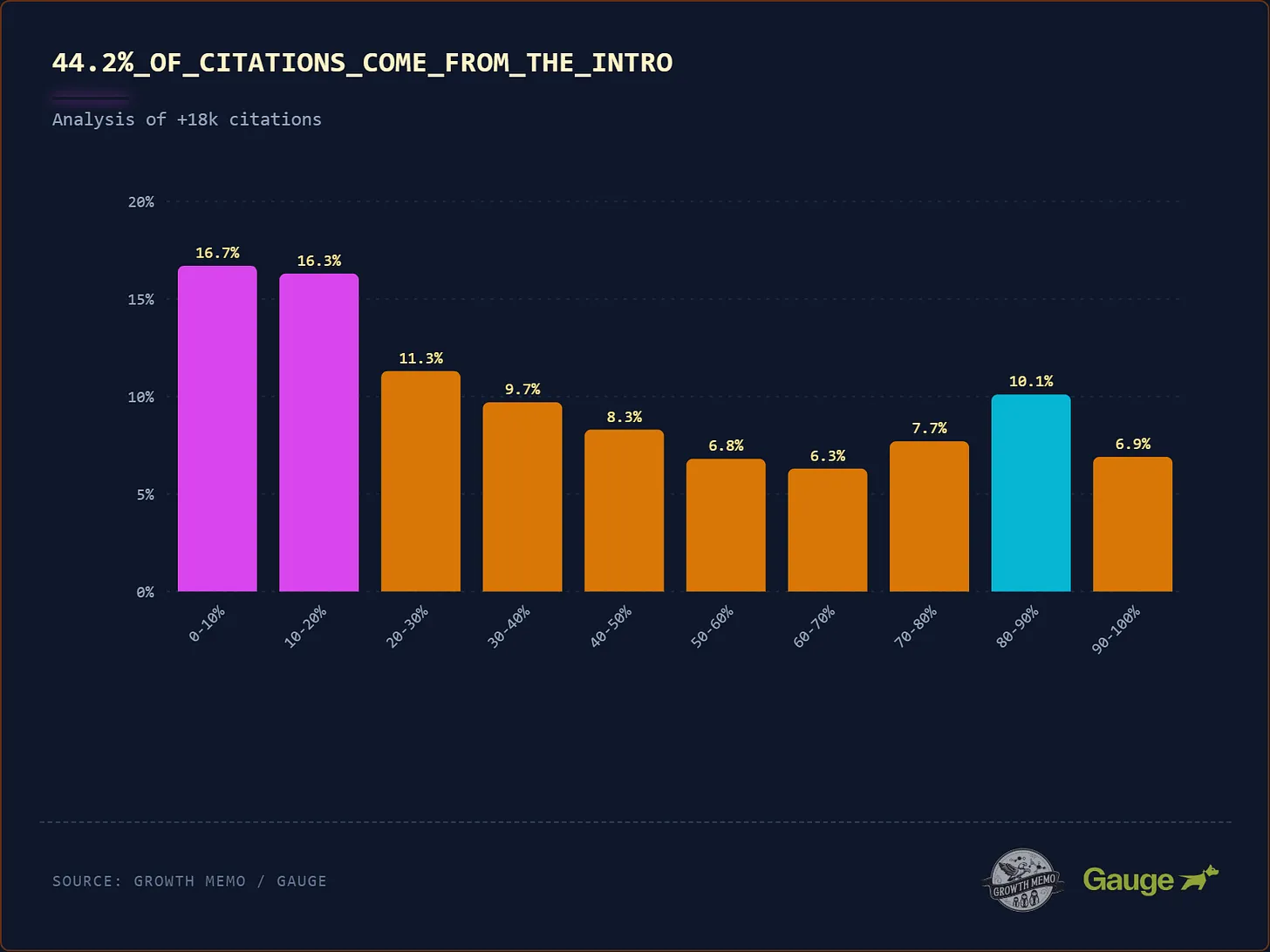
This reinforces the same structural signal emerging from embedding architectures:
- Answer first: put the definition or claim in the first sentence of the section.
- Entity density: name the entity early and consistently.
- Factual language: prefer declarative phrasing over hedged or rhetorical copy.
- Chunk completeness: each section should stand alone if extracted.
Kevin’s empirical observations and the architectural disclosures from Perplexity, Google, and OpenAI converge on a single reality:
Citation behavior is downstream of retrieval competitiveness.
If a passage is easy for machines to understand and trust, it is more likely to be retrieved, selected, and cited.
AI Spam, Usefulness, and the New Quality Bar
Google’s recent updates and spam policies clarify an important point: AI-generated content is not automatically penalized. Scaled, low-value content designed to manipulate rankings is.
In Google’s March 2024 announcements and updated spam policies, the focus is explicitly on practices like scaled content abuse (mass-producing unoriginal or low-value pages), expired domain abuse, and site reputation abuse (often discussed as “parasite SEO”).
This is where AI spam enters the picture.
As Lily Ray and other search quality analysts have repeatedly warned, many “GEO hacks” and scaled AI playbooks are simply spam patterns wearing new clothes. Thin pages, template-driven rewrites, doorway-style expansions, artificial refreshes, and other low-usefulness tactics can deliver short-term gains but create long-term risk.
Why usefulness is now machine-detectable
Modern retrieval stacks (dense retrieval + reranking + synthesis) evaluate signals that correlate strongly with usefulness, including:
- semantic specificity
- entity clarity
- informational completeness
- factual grounding
- structural coherence
Content that is thin, generic, or overly templated tends to produce weaker semantic signatures in vector space. Conversely, content that demonstrates depth and clarity produces denser and more discriminative embeddings.
Usefulness is case-dependent, but measurable
Usefulness depends on intent and audience, but there are practical ways to measure it during generation and QA:
- Information Gain: does the page add unique claims, examples, constraints, or data versus the top retrieved set?
- Task Completion: can a user finish the job with this page (steps, requirements, choices, outcomes)?
- Verifiability: are key claims backed by primary sources, standards, dates, numbers?
- Entity Integrity: does each section name the entity and its attributes clearly, with consistent terminology?
- Coverage vs Noise: does the page cover the intent fully without padding or filler?
These are not just editorial heuristics. They map to what retrieval systems can detect.
From Content to Reasoning Traces
To make this concrete, consider the difference we observe between a pure vector-based response and an RLM-on-KG grounded response when answering the same question about GS1 Digital Link.
RLM-on-KG grounded response:
GS1 Digital Link is a standard designed to serve as the future of product identification and digital connectivity. According to the provided passages, this standard is used to enhance traceability, streamline supply chains, and provide instant access to specific product details. For businesses, implementing GS1 Digital Link acts as a strategic roadmap to boost efficiency and gain a competitive edge by improving how products are identified and connected digitally.
Pure vector-based response:
GS1 Digital Link is a standard designed to enhance product identification and digital connectivity by providing instant access to product details. According to the provided passages, this standard is intended to streamline supply chains and enhance traceability, offering a strategic roadmap for business leaders to boost efficiency and gain a competitive edge. While the passages describe it as the future of product identification, they do not provide specific technical details on how the standard is structured or implemented beyond its general impact on business operations and supply chain management.
These differences are not only observable qualitatively in generated answers. They can also be explored experimentally at the embedding level. When passages are embedded across different retrieval models, clearer entity grounding and stronger semantic specificity tend to produce tighter semantic neighborhoods around the intended concept, while generic or weakly anchored text drifts into broader and noisier neighborhoods.
What this difference reveals
Both answers are broadly correct. However, the RLM-on-KG version is semantically tighter and more decision-oriented, while the pure vector version shows typical retrieval-only artifacts.
We consistently observe that KG-grounded reasoning produces:
- stronger entity centering (the subject stays stable)
- cleaner narrative flow
- fewer defensive hedges
- more actionable positioning language
By contrast, pure vector pipelines often introduce:
- hedging language (“the passages describe…”)
- summarization drift
- weaker entity anchoring
- higher risk of semantic dilution
Why embeddings alone are not enough
Dense retrieval is extremely effective at finding relevant text, but it does not guarantee:
- entity disambiguation
- relational consistency
- multi-step reasoning stability
This is exactly where the RLM-on-KG pattern becomes powerful. The Knowledge Graph acts as a stabilizing substrate that helps the model maintain entity identity and attribute coherence across the reasoning trace.
In our experiments, the practical pattern is clear:
Better graphs → cleaner reasoning → more useful answers.
This does not replace embeddings. It amplifies them by reducing ambiguity during synthesis.
In our work with large-scale data and Knowledge Graphs, we therefore analyze content not just as text to be indexed, but as fuel for reasoning traces.
In our work with large-scale data and Knowledge Graphs, we increasingly analyze content not just as text to be indexed, but as fuel for reasoning traces.
This is also consistent with what we see in our RLM-on-KG experiments.
When the model’s retrieval layer is anchored to a cohesive entity graph (clear entity identities, stable attributes, explicit relations), we consistently observe:
- higher grounding quality: answers reference the right entities and attributes more reliably
- fewer semantic collisions: less mixing of similar entities and fewer internal contradictions
- better multi-step coherence: chains of reasoning remain consistent across steps because the model can “return to” canonical nodes
- more useful outputs: recommendations and explanations become more actionable because constraints and relationships are explicit
The practical takeaway is simple:
A cohesive entity graph increases the usefulness of generated content because it gives retrieval and reasoning a stable substrate.
Well-structured content enables models to:
- anchor entities precisely
- follow logical relationships
- extract verifiable claims
- synthesize grounded answers
The embedding research from Perplexity, Google, and OpenAI provides mathematical evidence for this shift.
“Good” content is no longer judged only by human heuristics or traditional ranking signals. It is detectable in vector space through:
- semantic density
- contextual coherence
- entity consistency
- evidential grounding
This is why usefulness is increasingly measurable, even when content is produced with or by AI.
The winners in the GEO era will not be the teams that simply scale content production. They will be the teams that engineer content to support high-quality machine reasoning.
Why this matters for the Reasoning Web
From a WordLift perspective, this research validates a broader shift we have been tracking. We are moving from:
PageRank → PassageRank → Semantic Retrieval → Agentic Reasoning
In this new stack:
- Knowledge Graphs provide canonical entities.
- Structured data provides machine readability.
- Embeddings provide conceptual retrieval at massive scale.
- Agents perform synthesis and action.
Visibility is no longer just about being indexed. It is about being retrievable, understandable, and fundamentally trustworthy at the passage level.
The Bottom Line
The architectural updates from Perplexity, Google, and OpenAI confirm a shift in how the web is being read by machines.
In modern search systems:
- Embeddings help determine what content is semantically relevant.
- Retrieval systems decide which passages are considered.
- Trust signals influence what ultimately gets cited.
This does not replace the foundations of search. Crawling, indexing, links, and quality signals still matter. But as AI systems increasingly mediate discovery, the ability of content to be clearly understood, retrieved, and verified becomes more important.
Embedding-based retrieval is therefore becoming an important layer in how information surfaces across the AI web.
For publishers and content teams, the implication is not to chase shortcuts, but to reinforce what good SEO has always encouraged: clear semantic structure, explicit entities, verifiable information, and genuinely useful content.
As search becomes increasingly agent-mediated, these qualities make content easier for both people and machines to understand and trust.
To support this analysis, I also built a small Colab test bed to compare how snippets are represented across Perplexity, OpenAI, and Google embeddings.