
AI models don’t read content the way humans do.
They don’t watch your videos. They don’t scroll your feeds. They don’t absorb the ~vibe~ of your Instagram aesthetic, or feel the energy of your TikTok. They extract. They pull structured information from text (transcripts, captions, metadata, descriptions) and use that extracted material to construct answers.
This fundamental difference between human consumption and machine extraction explains one of the most important patterns in AI search: why some content gets cited constantly, while similar content (even on the same platform) gets ignored entirely.
I call this the Extractability Principle: the content that gets cited is the content that gives AI models something to pull from.
This isn’t about quality in the traditional sense. A beautifully produced video with no transcript is less extractable than an ugly video with detailed captions. A perfectly designed Instagram post with minimal text is less extractable than a cluttered carousel with dense captions. A viral tweet with a hot take is less extractable than a boring Reddit thread with step-by-step instructions.
Extractability is the new optimization target for AI visibility. Understanding it changes how you think about every piece of content you create.
Agents Are the New First-Class Citizens of the Internet
For 30 years, we designed content for humans. Every decision (layout, visuals, tone, structure) was optimized for human attention and human comprehension.
That reality isn’t ending, but humans are now getting a co-pilot.
When someone asks ChatGPT for a product recommendation, the model doesn’t send them to your website to browse. It retrieves information from across the web, synthesizes an answer, and presents it directly. Your content’s job is now to be useful to the agent answering their question.
When someone asks Perplexity to compare options, the model scans hundreds of sources, pulls relevant chunks, and assembles a response. Your content is competing for extraction, not clicks.
This is a real shift in how the search-and-retrieval process works. You now have a new audience persona to design for, and it behaves nothing like a human:
Agents read everything but experience nothing. An agent processes your entire article in milliseconds, but it will never “feel” your carefully crafted emotional arc. It won’t appreciate your visual design or your brand voice. It extracts factual claims relevant to the query it’s answering. That’s it.
Agents have zero patience for ambiguity. Humans infer meaning from context and read between the lines. Agents take your words at face value. “It’s the best option for most people” is useless when the agent doesn’t know what “it” refers to, who “most people” are, or what “best” means here.
Agents extract fragments, not wholes. Your article might be 3,000 words, but only 47 get cited. Those 47 words need to work without the other 2,953.
Agents trust structure over style. A well-formatted article with clear headers and explicit claims is more extractable than a beautifully written piece with flowing prose and buried information. Structure is signal. Style is noise… at least for this audience.
|
How they read |
Experiences the full arc (tone, emotion, pacing) |
Processes everything in milliseconds; extracts factual claims only |
|
Handling ambiguity |
Infers meaning from context and reads between the lines |
Takes words at face value; vague references become useless |
|
Unit of use |
Absorbs the whole piece as a coherent narrative |
Retrieves isolated chunks (i.e. 20-60 words from a 3,000-word article) |
|
Responds to |
Voice, personality, visual design, emotional resonance |
Clear structure, explicit claims, named entities, front-loaded answers |
|
Design goal |
Style is substance |
Structure is signal; style is noise |
Don’t get me wrong: designing for agents doesn’t mean abandoning human readers. The best content in this era is dual-native: built to engage humans and be extracted by machines simultaneously.
Fortunately, most extractability optimizations (clear structure, explicit claims, front-loaded information) also make content better for humans. Where the two audiences diverge, you make deliberate choices. Sometimes you add a sentence that’s purely for machine extraction: an explicit definition, a structured comparison, a self-contained summary.
Slightly redundant for humans, dramatically useful for agents.
Here’s the part most content creators miss entirely: AI models don’t cite your entire page. They cite a chunk of your page.
When a retrieval system needs to answer a user’s query, it doesn’t pull entire URLs into its context window. That would be inefficient (and expensive). Instead, it breaks content into smaller semantic units (aka “chunks”) and retrieves only the specific chunks relevant to the query.
A 2,000-word article might become 15-30 distinct chunks. Each chunk gets embedded (converted into a numerical representation of its meaning), stored, and matched against incoming queries independently. The model uses the retrieved chunks to generate its response.
This has a counterintuitive implication: a mediocre page with one excellent chunk can outperform a great page with no standout chunks. The overall quality of your article matters less than whether the specific segment that gets retrieved for a relevant query is well-constructed.
The Chunk Independence Problem
This creates what I call the chunk independence problem. Each chunk of your content must stand alone.
Here’s a typical example. A product review article includes this paragraph:
After evaluating multiple options, we decided to go with this platform for several key reasons. The integrations were exactly what we needed: it connects seamlessly with our existing stack, including the tools we use for marketing automation and customer support.
A user asks: “What CRM has good integrations?” The retrieval system pulls this paragraph. But it’s useless. It doesn’t name the CRM (that was in the header), doesn’t specify which integrations, and doesn’t name the tools. The chunk is completely dependent on surrounding context that won’t be retrieved with it.
Now compare that to a chunk-optimized version:
HubSpot CRM offers native integrations with over 1,400 tools, including marketing platforms like Mailchimp and ActiveCampaign, customer support tools like Zendesk and Intercom, and productivity apps like Slack and Google Workspace. Setup typically takes under 15 minutes per tool with no coding required.
Same information. But this version names the product, specifies integrations with examples, and includes concrete details. It works extracted in complete isolation, which is exactly how it will be used.
The practical rule is straightforward: every section of your content should pass the independence test:
- If this section were extracted alone, would it make sense?
- Would it answer the question?
- Would a reader (or agent) know what you’re talking about without reading anything else on the page?
Influencing How Your Content Gets Chunked
You can influence where chunk boundaries fall by using explicit structural signals. Headers create natural breaks; most chunking algorithms treat them as boundary markers. Short paragraphs chunk cleaner than long ones. Lists and tables tend to chunk as units, keeping related information together.
Think of structure as instructions for how your content should be segmented. The clearer your structural signals, the more likely your content gets chunked into meaningful, self-contained units rather than arbitrary fragments.
Extractability can be seen as a spectrum with seven contributing factors, each of which I’ve identified through analyzing citation patterns across millions of data points in our Goodie AI research.
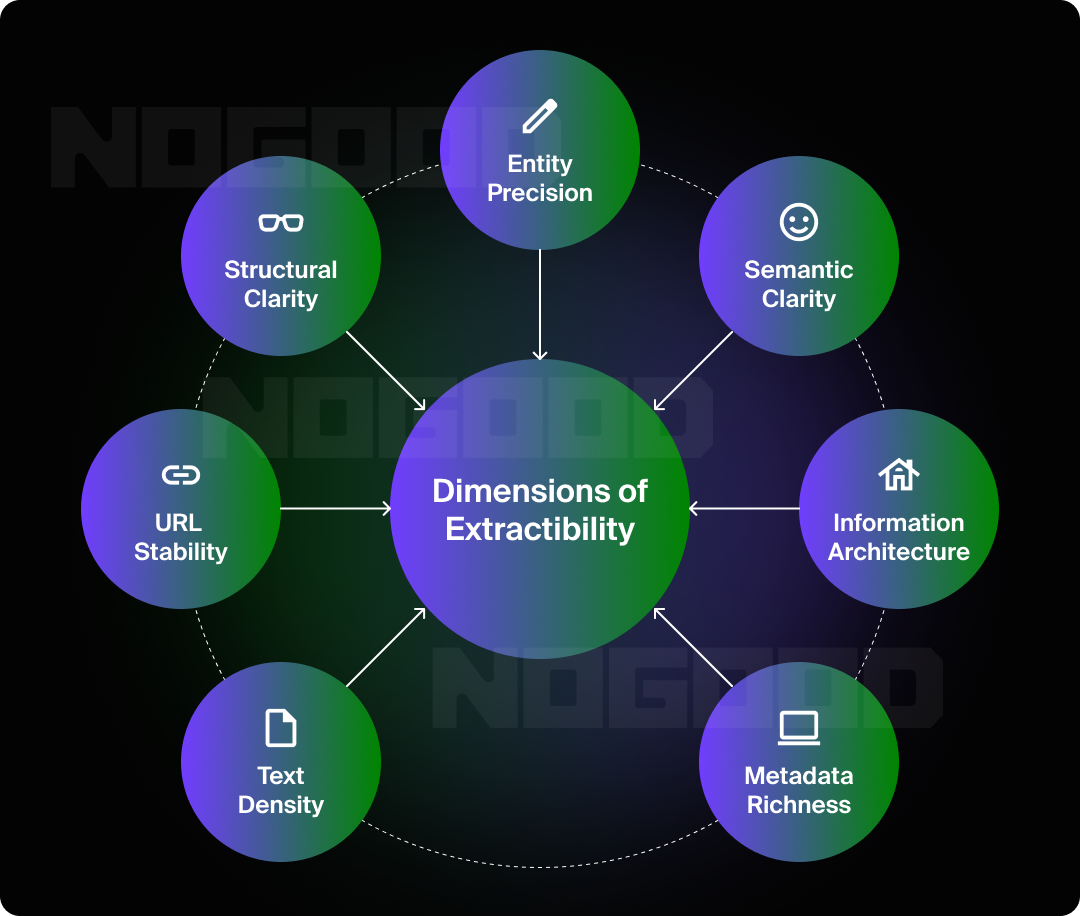
1. Text Density
Text density is the volume of extractable text per content unit:
- A 15-minute YouTube video produces a transcript of several thousand words: definitions, explanations, comparisons, step-by-step instructions that map cleanly to user queries.
- A 30-second Short might generate 50-100 words of transcript, fragmented and context-dependent.
This is the most fundamental dimension. It explains the 51:1 gap between YouTube Long Videos and Shorts more than any other factor. More text means more material for models to match against queries, and more potential chunks to retrieve.

Longer isn’t automatically better, though. A 5,000-word article that rambles is less extractable than a 1,500-word article with clear, information-dense paragraphs.
Density refers to information per word, not word count.
2. URL Stability
URL stability means ensuring that your content resolves to a persistent, accessible address. A LinkedIn Article has a permanent URL that persists indefinitely. An Instagram Story disappears in 24 hours and leaves nothing for retrieval systems to find.
Stable URLs serve two functions: they allow content to be discovered and indexed in the first place, and they allow models to cite it with a reference users can actually visit.
No URL, no citation.
3. Structural Clarity
Structural clarity refers to how well your content is organized into discrete, parseable units that create meaningful chunk boundaries. A well-structured article with headers, distinct paragraphs, and logical flow helps retrieval systems segment content into units that can be independently evaluated.
A wall of text with no formatting forces chunk boundaries to fall arbitrarily, potentially even mid-thought, or mid-argument. YouTube chapters are the clearest example of structural clarity in action. When you add chapters, you’re telling retrieval systems: here are the distinct topics, here’s where each starts, and each segment is semantically self-contained.
4. Entity Precision
Entity precision requires using clear, consistent, unambiguous names for the things you’re discussing. When you refer to your product by five different names, you fragment the entity signal. When you use “our solution” or “the platform” instead of the actual product name, you remove the signal entirely.
This is especially critical for chunk independence. A chunk that says “the platform” without naming it is useless when extracted in isolation, which, again, is the default.
5. Semantic Clarity
Semantic clarity is how unambiguous your statements are when standing alone.
Compare: “It’s definitely the best option for most people in this situation” vs. “The Sony WH-1000XM5 offers the best noise cancellation for daily commuters under $400.”
The first is meaningless without context. The second names the entity, specifies the claim, identifies the use case, and provides a constraint. It can be extracted and cited without any surrounding text.
6. Information Architecture
Information architecture requires being intentional about where the most important information lives within your content. The inverted pyramid from journalism (key claim first, supporting details after) is highly extractable. The answer appears early, clearly stated, where retrieval systems are most likely to find and chunk it effectively.
Content that buries the point at the end, or requires reading the full piece to understand, gets passed over. Models may extract earlier, less relevant material, or simply move on to a source that front-loads the answer.
7. Metadata Richness
Metadata richness refers to the extractable information outside your main content body: titles, descriptions, tags, alt-text, captions, chapter markers, schema markup.
A YouTube description is metadata. It’s not the video itself, but it provides extractable text that models use to understand and cite the content. Metadata often becomes its own chunk, retrievable for relevant queries independently of the main content.
Treat metadata as primary content, not an afterthought. Write descriptions and captions as if they might be the only thing a model reads… because sometimes they are.
Why Engagement Metrics Mislead
The Extractability Principle creates a real tension with traditional content strategy. Most social content is optimized for engagement, and engagement optimization often works directly against extractability.
- Brevity over density. Engagement rewards quick hits. Extractability rewards information-rich depth.
- Emotion over information. Viral content succeeds through emotional resonance, but emotional content is frequently vague, context-dependent, and low on extractable facts.
- Visual over textual. The most engaging Instagram posts rely on imagery with minimal caption text. Beautiful for humans. Nearly invisible to retrieval systems.
- Ephemeral over permanent. Stories and disappearing posts drive engagement through scarcity and urgency. They leave nothing behind for models to cite.
- Personality over precision. Human audiences love voice and authentic expression. Agents want clear claims, specific entities, and unambiguous statements.
This doesn’t mean engagement is dead. It still matters for building audience, generating revenue, and creating brand affinity. But engagement is not a proxy for AI visibility. The content that wins on social platforms is often not the content that wins in AI search. These are two different games now, and you need to play both.
Different platforms have fundamentally different extractability baselines.

- High extractability: Reddit is text-native by design: posts, comments, threaded structure with natural chunk boundaries (each comment is essentially a self-contained unit). Upvotes provide relevance signals.
- Side note: This explains why Reddit is the only social platform cited at meaningful volume by all 10 major AI surfaces in the dataset. LinkedIn Articles and YouTube Long Videos also score high, with stable URLs, structured formatting, and substantial text density.
- Medium extractability: LinkedIn Feed Posts, YouTube Shorts, and Instagram Reels. They have text, but less of it. URLs exist but get indexed less aggressively. Formats are optimized for quick consumption, not information density.
- Low extractability: Instagram static posts (image-primary, minimal text), TikTok videos (access constraints plus short-form; 80% of TikTok citations point to profile pages, not individual videos), X/Twitter posts (character-limited, context-dependent, coupled primarily to Grok). Stories and ephemeral content across all platforms have near-zero extractability.
You can evaluate any piece of content by running through these questions:
- Text density: If I stripped all visual and audio elements, how many words of substantive information would remain?
- URL stability: Does this content have a permanent, public URL that will exist six months from now?
- Structural clarity: Is this organized with clear sections that create natural chunk boundaries?
- Entity precision: Are key entities named explicitly and consistently in every section?
- Semantic clarity: Would each section make sense if extracted in complete isolation?
- Information architecture: Is the most important information near the beginning of each section?
- Metadata richness: Do the title, description, and captions provide extractable information beyond the main content?
- Chunk independence: If any segment of this were pulled without its surrounding context, would it still answer the question?
Content scoring high across all eight is highly extractable and likely to be cited. Content scoring low on multiple dimensions will struggle in AI answers regardless of quality or engagement.
Extractability doesn’t operate in isolation. It’s one layer in a broader stack that determines AI visibility:
- Layer 1: Access. Can the AI model reach your content at all? Platform coupling, licensing deals, and technical accessibility determine this. If a model can’t get to your content, nothing else matters.
- Layer 2: Indexing. Has your content been indexed? Stable URLs, crawlability, and time for discovery.
- Layer 3: Chunking. Has your content been segmented into meaningful units? Structural clarity, length, and format determine this.
- Layer 4: Extractability. Can the model extract useful information from each chunk? This is where the seven dimensions apply.
- Layer 5: Relevance. Do your extracted chunks match user queries? Entity coverage, keyword alignment, topical authority.
- Layer 6: Trust. Does the model trust your content as a source? Domain authority, third-party corroboration, source reputation.
Each layer filters. To get cited, your content must pass through all six. Extractability alone isn’t sufficient, but without it, nothing else in the stack matters.
Where This Is Going
A few trends are worth watching.
Multimodal models will expand what’s extractable. As models get better at interpreting images, understanding video beyond transcripts, and parsing audio directly, visual content will become more extractable. But text will remain the most reliable extraction signal for years.
Platforms will optimize for AI extraction. As AI search becomes a meaningful traffic source, platforms will build better transcript tools, richer metadata options, and structured formats designed for machine parsing. This is already starting.
Extraction will become a content discipline. The same way SEO became a distinct skill set from general marketing, extraction optimization will emerge as its own practice. Content teams will audit for extractability the way they currently audit for keyword coverage.
Agent-first content will emerge as a category. Some content will be created primarily for agent consumption, with human readability as secondary. FAQ schemas, structured data, and machine-readable specifications are early examples of this shift.
Competition for extractable positions will intensify. As more brands understand this, the bar will rise. Content that is merely extractable won’t be enough; it will need to be more extractable, more relevant, and more authoritative than competitors.
The Content That Survives
The Extractability Principle is ultimately about how information survives translation.
Your content exists in one form (a video, an image, a post). AI systems translate it into a different form (text tokens, embeddings, semantic chunks) before deciding whether to cite it. Extractability measures how much of your original information survives that translation.
High-extractability content loses little. The claims, the entity references, the structured arguments all come through intact. The model understands what you’re saying, chunks it meaningfully, and cites it accurately.
Low-extractability content loses most of its value. The visual impact, the emotional resonance, the contextual meaning… none of that survives translation. The model pulls fragments, creates meaningless chunks, and moves on to a source that’s easier to work with.
You’re no longer creating just for human audiences who experience your content directly. You’re creating for AI agents who extract, chunk, retrieve, and present your content to users who may never visit your page. These agents are the new first-class citizens of the internet; the intermediary between your content and your customer. Designing for them isn’t optional anymore. It’s the new baseline.
The brands that get this will build content that works on both levels: engaging for humans, extractable for machines. The brands that don’t will lose the citation layer to competitors who do.
Extractability isn’t everything. But for AI search, it’s the starting point.
The Extractability Principle is based on research from Goodie AI analyzing 1.8 million social citations across 45.2 million total citations and 10 AI surfaces from September 2025 to February 2026.