
Ontologies were created to make human knowledge understandable to machines. In the agentic era, their role expands: they are no longer only formal artifacts for interoperability, but runtime structures that help AI agents retrieve, validate, remember, plan, and act without losing meaning.
The primary consumer of ontologies is no longer only a database, a search engine, or a symbolic reasoner. Increasingly, the consumer is an AI agent: a system that reads, retrieves, plans, calls tools, updates memory, generates language, and takes action. This changes what an ontology needs to be.
Ontologies began as a way to help machines understand human knowledge. In the age of AI agents, they are becoming the way humans keep machine intelligence grounded, inspectable, and useful.
The original trajectory: formal meaning for machines
The classical definition of an ontology is a “formal, explicit specification of a shared conceptualization,” a formulation associated with the foundational work of Tom Gruber and later refined by Nicola Guarino and Aldo Gangemi, who emphasized that ontologies are explicit conceptual models that capture domain meaning and support shared understanding, interoperability, and reasoning. An ontology makes the implicit structure of a domain explicit. It turns tacit human knowledge into a machine-readable model.
This vision became central to the Semantic Web articulated by Tim Berners-Lee, James Hendler, and Ora Lassila in their influential 2001 Scientific American article. They described a web in which information would carry well-defined meaning, enabling computers and people to work together more effectively.
RDF provided a graph model. RDFS and OWL provided vocabularies, classes, properties, and axioms. SKOS made thesauri and controlled vocabularies easier to publish as linked data. SHACL later introduced a practical way to validate the structure of RDF graphs.
The trajectory was clear: formalize the domain, publish the semantics, integrate the data, and let machines reason. This produced powerful ideas: identity through IRIs, explicit relations, distributed vocabularies, inferencing, linked data, and reusable knowledge models.
But ontology engineering was slow, required specialized expertise, and created a persistent gap between what humans wanted to say and what production systems could operationalize. Then LLMs arrived.
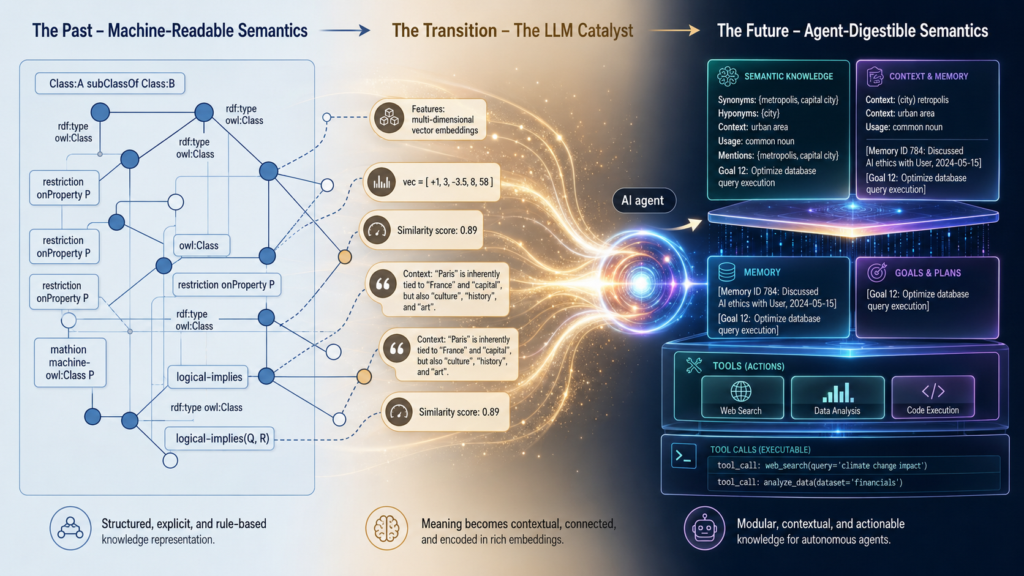
LLMs as an enabler of iterative ontology engineering
Large language models are changing ontology engineering because they can operate on the material from which ontologies are born: language. They can read documents, extract terms, propose classes, suggest definitions, identify candidate relations, generate competency questions, write documentation, and help validate whether a model captures the intended meaning of a domain.
This does not make ontology engineers obsolete. It changes their role. The ontology engineer becomes less of a manual modeler and more of an orchestrator of semantic workflows: guiding extraction, reviewing suggestions, resolving ambiguity, and deciding which parts of the domain need formalization.
Recent research on LLM-assisted ontology engineering shows activity across almost every phase of the ontology lifecycle. Research challenges such as LLMs4OL study how LLMs can support ontology learning tasks. Systems such as OntoGPT combine prompts, LLMs, and ontology-based grounding to extract structured knowledge from text. Research such as Agent-OM explores how LLM agents can support ontology matching through planning, memory, and tools.
Ontology engineering becomes conversational, iterative, and semi-automated. But the deeper change is not only in how ontologies are built. It is in how they are written.
From logic-first to agent-digestible ontologies
The original ontology stack privileged formal precision: classes, properties, domains, ranges, restrictions, cardinalities, and axioms. This remains essential. But LLMs are poor at consuming meaning through formal logic alone. They derive meaning from tokens, examples, descriptions, lexical cues, embeddings, tool schemas, and retrieved evidence.
This pushes ontology syntax toward a hybrid form: part formal model, part language interface.
Each class, property, entity, and shape increasingly benefits from richer natural-language fields. Properties such as rdfs:comment, skos:definition, skos:scopeNote, skos:example, schema:description, schema:abstract, and dcterms:description are no longer merely documentation. They are semantic affordances for language models.
In a classical ontology, a comment helps a human understand a class. In an agent-oriented ontology, the same comment can influence retrieval, extraction, disambiguation, tool selection, grounding, and generation. The ontology becomes readable by both symbolic systems and language models.
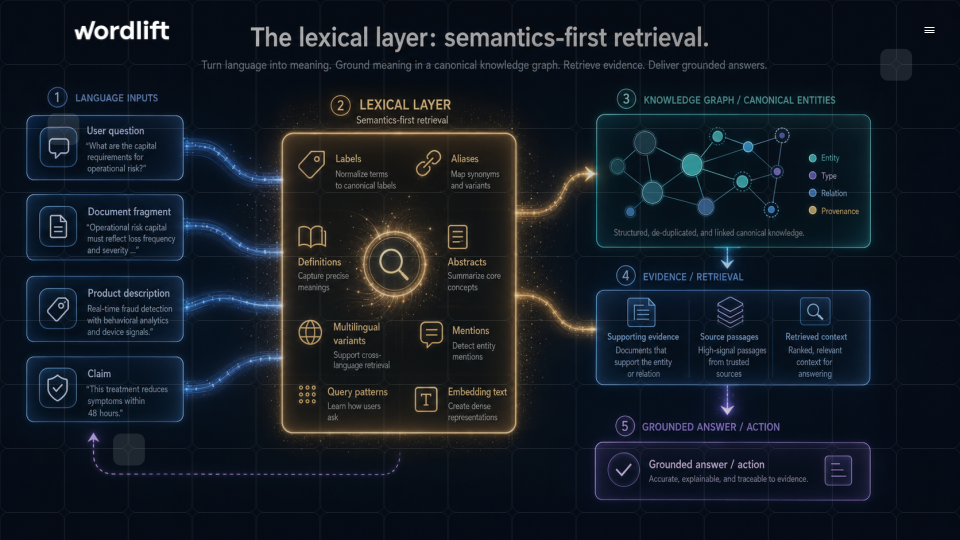
The lexical layer and semantics-first retrieval
As Microsoft recently argued in its work on retrieval for the agentic web (Web IQ), the quality of an AI system increasingly depends on its ability to connect generated outputs to reliable, relevant, and verifiable information. Retrieval is becoming the mechanism through which agents maintain alignment with reality and make trustworthy decisions.
A formal ontology defines the meaning of entities and relationships, but an agent also needs to discover those entities from natural language, retrieve supporting evidence, and reconnect retrieved information to a structured understanding of the domain. The challenge is not only semantic modeling but semantic grounding.
In our work at WordLift, we have seen the need for an additional layer that sits between the formal graph and the agent: a lexical graph and retrieval layer. The formal ontology defines the meaning of things. The lexical layer defines how those things appear in language, how they are mentioned, how they are searched, how they are confused, and how they can be connected to evidence.
An AI agent does not usually start from a SPARQL query. It starts from a user question, a task, a product description, or a fragment of conversation. The agent needs to move from language to entities, from entities to evidence, and from evidence back to a grounded answer or action.
This is why, in SEOVOC, we introduced attributes such as seovoc:embeddingText and seovoc:embeddingValue. The seovoc:embeddingText property defines the textual representation that should be embedded for an entity. The seovoc:embeddingValue stores or references the resulting vector representation.
The ontology is no longer only describing the entity. It is describing how the entity should enter vector space. It tells the system what language should become memory, which semantic signals should be preserved, and how retrieved evidence should reconnect to canonical entities in the graph.
The ontology starts to carry the instructions for memory formation.
Vector search alone is not memory. Vector search retrieves similarity. Ontological memory retrieves similarity in relation to identity, type, provenance, context, time, and task. A memory layer must be a structured retrieval environment where lexical, symbolic, and vector representations reinforce each other.
Validation: less fragile negation, more executable constraints
Classical ontology engineering often uses negative constraints: disjoint classes, complement classes, negative property assertions, and closed-world validation patterns. These remain valuable for formal reasoning. But they are difficult for LLMs to process reliably in the generative context.
Negation-heavy constraints should be executed in validation layers, not loosely interpreted in generative context.
An agent-oriented ontology expresses more of the world in terms of what is possible, expected, allowed, and required. Negation belongs in SHACL validation, policy checks, competency-question tests, and deterministic evaluation pipelines.
SHACL started as a way to validate RDF graphs, but its role is broadening. The SHACL 1.2 specification explicitly frames shapes as useful for validation, inferencing, domain modeling, generating ontologies to inform agents, building user interfaces, generating code, and integrating data.
As Veronika Heimsbakk, author of SHACL for the Practitioner, emphasizes: making ontologies operational requires treating semantic assets as executable specifications. Ontologies become practical instruments that guide how data is created, exchanged, validated, and consumed by applications and agents.
OWL helps us define the conceptual structure of the world. SHACL helps us define what valid, usable, and actionable data looks like in practice. For AI agents, this distinction is essential.
Ontology, tools, and agent workflows
Ontology design is moving closer to agent workflow design. Frameworks such as LangGraph represent agentic systems as graphs of state, nodes, and edges. This looks familiar to ontology engineers, but it is not the same kind of graph. An ontology graph describes the domain: entities, types, relations, and meaning.
The lexical graph facilitates the discovery of entities and helps agents move from language and mentions to the canonical concepts represented in the knowledge graph. The action graph bridges the nouns represented in vocabularies such as Schema.org and the GS1 Web Vocabulary with the verbs and capabilities exposed through protocols like the Universal Commerce Protocol, including those described in its .well-known manifest. It describes the work: tasks, tools, states, transitions, decisions, retries, outcomes, and the actions an agent can perform on entities in the graph.
The emerging pattern is to connect the two. The semantic graph tells the agent what the world means. The execution graph tells the agent what to do next. The validation layer checks whether the action is allowed and whether the resulting data is valid.
One of the strongest signs of this evolution is the emergence of ontology-to-tools compilation. Instead of giving an LLM a free-form prompt and asking it to produce structured data, the ontology can be compiled into callable tools that enforce semantic constraints during the generation process. The ontology becomes an executable contract.
In an agentic system, this connects naturally with protocols such as MCP. MCP tools expose schemas, descriptions, and callable operations to models. If these tools are generated from or aligned with an ontology, the agent knows not only that a tool exists, but what it means, what entity types it operates on, what constraints apply, and how the result should update the knowledge graph.
The Semantic Web wanted machines to understand data. The agentic web needs machines to act on data without losing meaning.
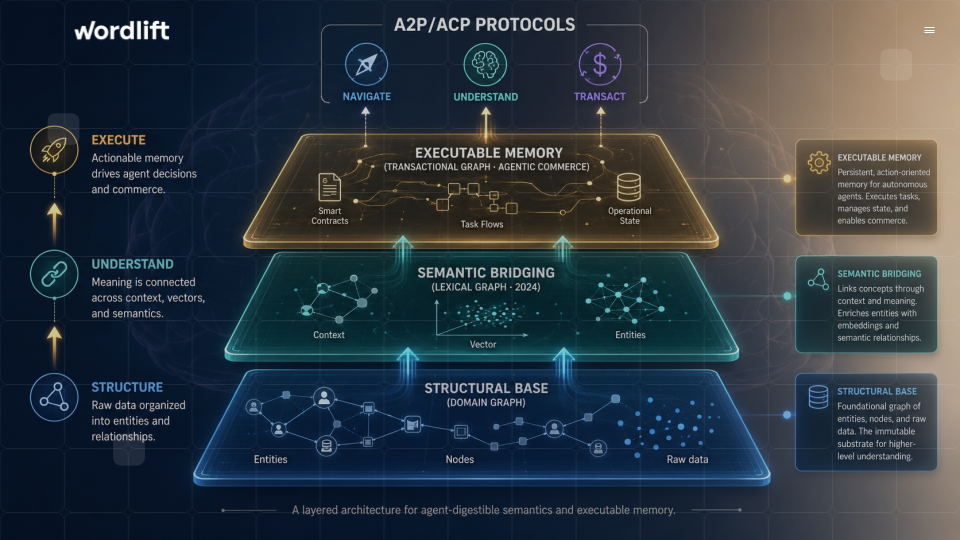
Ontologies as memory
LLMs are stateless by default. RAG systems add retrieval, but most retrieval is still based on static documents and similarity search. That is not enough for long-lived agents. Agents need memory that changes over time, preserves identity, tracks events, distinguishes current from outdated knowledge, and links facts to evidence.
Recent work on agent memory increasingly distinguishes semantic memory from episodic memory. Semantic memory stores stable knowledge: entities, concepts, relations, facts. Episodic memory stores experiences: events, observations, interactions, decisions, and changes over time. Research such as AriGraph explores graph-based memory structures for LLM agents, while systems such as Zep use temporal knowledge graphs as memory layers for enterprise agents.
An ontology can organize both. It defines what kinds of memories exist, how they relate to entities, how they are timestamped, what provenance they carry, and how they should be retrieved.
Instead of asking a model to consume a large flat context, recursive language modeling treats the graph as an environment to explore. The model decomposes the task, retrieves a first layer of context, identifies new entities or gaps, re-enters the graph with refined questions, and continues until it has enough grounded information to answer or act. The ontology guides the recursion: it tells the model which entity types matter, which relations can be followed, which evidence is acceptable, and when the answer is sufficiently grounded. This improves retrieval quality because the model is not merely looking for the nearest chunk. It is navigating a structured memory environment.
This is also helping us bring knowledge to edge devices, pushing structured memories closer to small language models that run directly on your phone. For example, WordLift’s Google AI Edge GraphQL integration enables ontology-backed knowledge retrieval in edge AI scenarios. In this setting, the ontology guides the recursion. It tells the model which entity types matter, which relations can be followed, which evidence is acceptable, which constraints apply, and when the answer is sufficiently grounded.
Ontologies as training and alignment assets
Ontologies are also becoming training and alignment assets, especially for smaller, private, domain-specific models. Instead of training only on raw documents, enterprises can use ontologies to provide structured training material: canonical concepts and definitions, entity types and relation patterns, examples and taxonomies, competency questions and reasoning paths, and retrieval and validation traces.
This makes the ontology a curriculum. A small language model can be trained or aligned on the conceptual structure of the domain. It can learn what matters, what terms mean, how concepts relate, how to classify entities, how to retrieve evidence, and how to produce outputs that conform to the graph.
Research on Large Ontology Models points in this direction, exploring how ontology-language pairs, instruction tuning, and ontology-grounded reasoning can support enterprise knowledge management and domain-specific model behavior.
This is especially important for vertical agents. In many enterprise settings, the goal is not to build a general intelligence but a reliable domain actor: an SEO agent, a product data agent, a procurement agent, a legal intake agent, a medical coding assistant, or a brand intelligence agent. For these systems, an ontology is not only a reference model. It is a training scaffold and an alignment layer.
The layered ontology stack
The ontology of the agentic era is layered. It still needs a domain layer, but that is no longer enough. A practical stack looks like this:
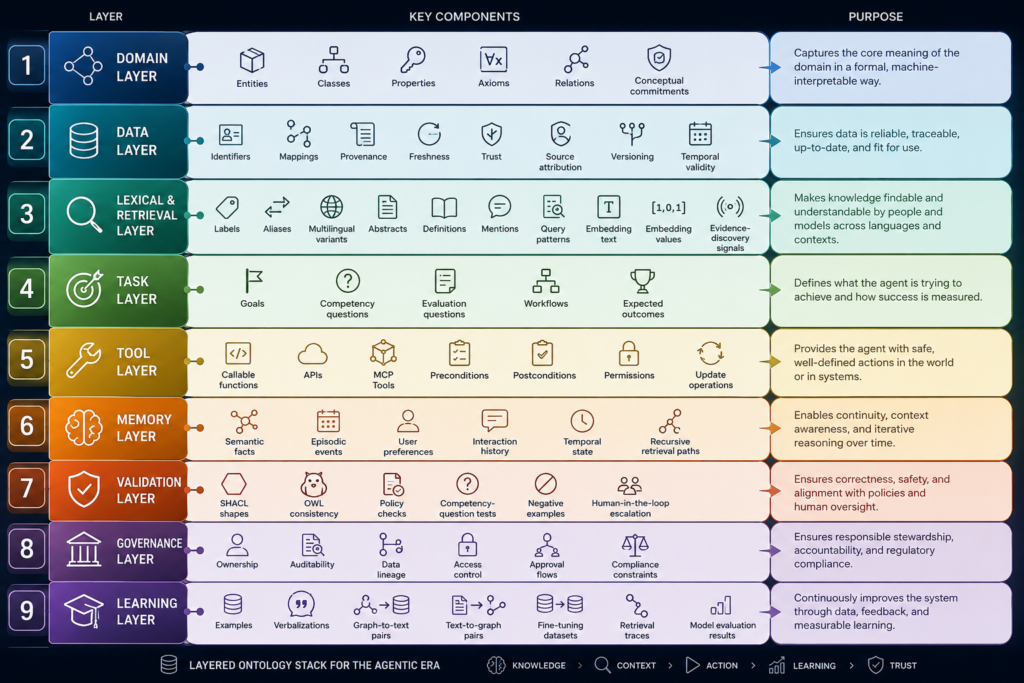
- Domain layer: entities, classes, properties, axioms, and conceptual commitments.
- Data layer: identifiers, provenance, freshness, trust, versioning, and temporal validity.
- Lexical and retrieval layer: labels, aliases, definitions, embedding text, embedding values, and evidence-discovery signals.
- Task layer: goals, competency questions, workflows, and expected outcomes.
- Tool layer: callable functions, APIs, MCP tools, preconditions, postconditions, and permissions.
- Memory layer: semantic facts, episodic events, temporal state, and recursive retrieval paths.
- Validation layer: SHACL shapes, OWL consistency, policy checks, and competency-question tests.
- Governance layer: ownership, auditability, data lineage, access control, and compliance constraints.
- Learning layer: examples, graph-to-text pairs, fine-tuning datasets, retrieval traces, and evaluation results.
This stack changes the central question of ontology design. We need to ask:
What information, constraints, contextual signals, and memory structures does an agent need to maximize accuracy, use tokens efficiently, remain inspectable, and reliably retrieve, validate, maintain, and apply knowledge within this domain?
What changes in ontology design practice
This leads to several practical design principles.
- Rich natural-language surfaces. Every important class and property should have labels, definitions, abstracts, examples, and usage notes. They are part of the model interface.
- Separate logical semantics from agent instructions. Formal axioms should remain formal. Agent-facing descriptions should explain how a concept is used, when it applies, what evidence supports it, and how it differs from adjacent concepts.
- Design embedding text deliberately. The text that enters vector space should be curated, canonical, multilingual where needed, and connected to the entity it represents.
- Operationalize negation. Do not rely on the model to interpret complex negative logic in context. Put negative constraints into SHACL, tests, and deterministic validation layers.
- Map ontology modules to workflows. If an agent needs to perform a task, the ontology should expose the entities, evidence, tools, states, and constraints involved.
- Turn competency questions into evaluation assets. They are not only requirements. They are regression tests for the ontology and for the agent.
- Attach provenance to every generated fact. Agents need to know not only what is true, but where it came from, when it was observed, how it relates to other facts, and whether it is still valid.
- Design for memory. Model time, events, updates, user preferences, and recurring retrieval paths.
- Treat ontologies as training assets. If we want smaller models to act reliably in a domain, the ontology should produce examples, traces, and structured curricula.
Conclusion: ontologies as the control plane for AI agents
The evolution of ontology design can be understood as a move from machine-readable semantics to agent-digestible semantics. Machine-readable semantics made knowledge explicit for software. Agent-digestible semantics makes knowledge usable by systems that read, retrieve, reason, generate, call tools, and update memory.
The convergence of language models and formal knowledge representation, often described as neuro-symbolic AI, is not a replacement of one paradigm by another. It is an integration where semantic capital becomes a durable organizational resource.
Ontologies provide identity where language provides variation. They provide structure where embeddings provide similarity. They provide validation where generation provides fluency. They provide provenance where answers need evidence. They provide memory where context windows are temporary. They provide governance where agents need permission to act.
The ontology is no longer just a map of the domain. It is the control plane for AI agents.
In the Semantic Web, ontologies helped machines understand the world. In the agentic web, ontologies help agents act in the world without losing meaning.