
In the dot-com era, free users paid with attention. Ads, banners, tracking, monetisation loops. The information space got crowded and cheap.
In the AI era, the currency is trust. And the economics work the same way: when inference, search, browsing, and retrieval all have a cost, product experiences diverge. Save money, and your information space may become more exposed to stale memory, weak grounding, and AI slop recycled as confident synthesis.
That is not just a product tradeoff. It has ethical implications. When a lower-cost AI experience systematically surfaces less-verified information to users who cannot tell the difference, the asymmetry stops being a feature gap and starts being a trust violation.
That is the hypothesis behind what we looked at. And the data, while limited, is directionally hard to ignore.
What we compared
We analysed 56 ChatGPT enterprise traces where the SSE stream exposed the model path. This is not a direct free-vs-paid subscription export. We did not classify users by billing records. We classified traces by the model slug visible in the stream:
gpt-5-3-mini→ free-like proxygpt-5-3/gpt-5-5-thinking→ paid-like proxy
Only 56 of 131 total enterprise traces had usable model-slug metadata. The sample is small. Read this as a directional signal, not a final verdict.
The gap is grounding, not schema vocabulary
The first thing we expected to find was a schema-awareness gap. We did not find one.
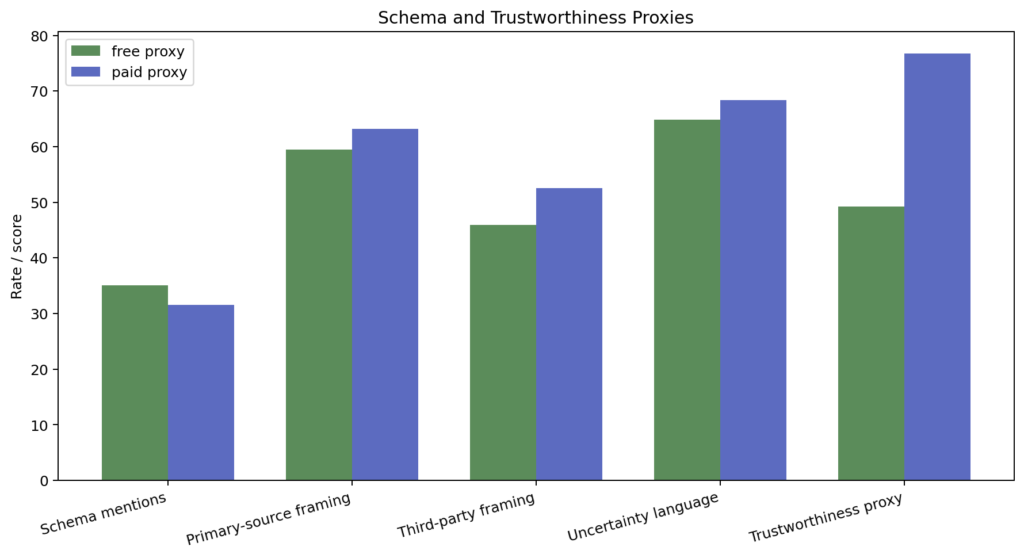
Schema-related language appeared at nearly identical rates across both groups: 35.1% free-like, 31.6% paid-like. Primary-source framing, third-party framing, uncertainty language: all broadly similar (see chart below).
Both groups can talk about structured data, machine-readability, and evidence quality. The vocabulary is there.
What is not equal is whether the model actually goes and checks.
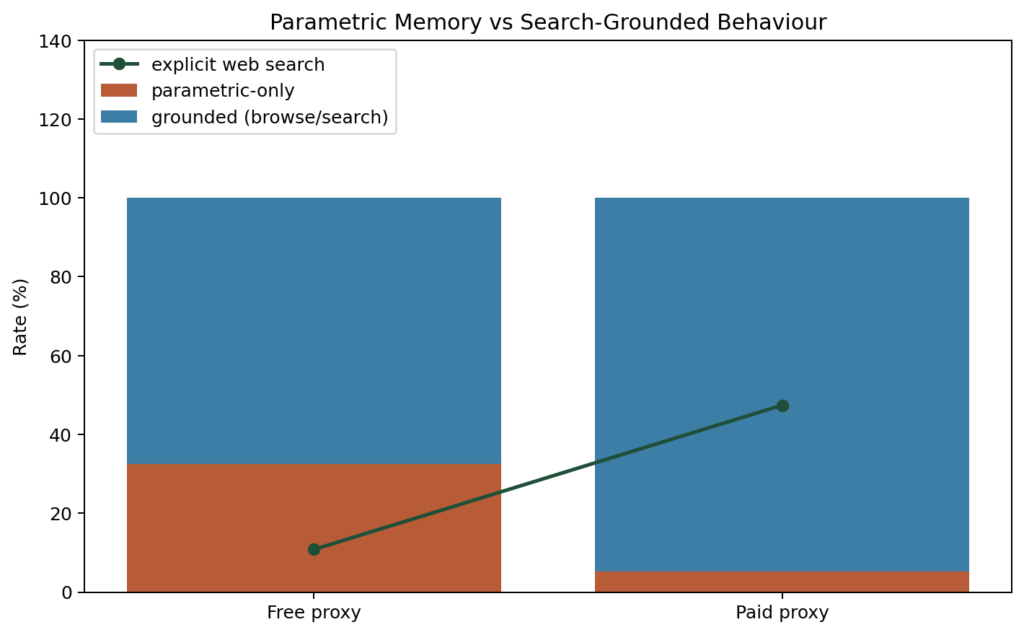
The grounding split tells a completely different story:
| Metric | Free-like | Paid-like |
|---|---|---|
| Web search rate | 10.8% | 47.4% |
| Parametric-only rate | 32.4% | 5.3% |
| URLs per 1,000 chars | 0.93 | 3.38 |
| Citations per 1,000 chars | 0.14 | 0.78 |
| Trustworthiness proxy | 49.2 | 76.8 |
The free-like group was not shorter; average answer length was actually slightly higher (3,360 vs 3,117 characters). The issue is not verbosity. It is evidence density.
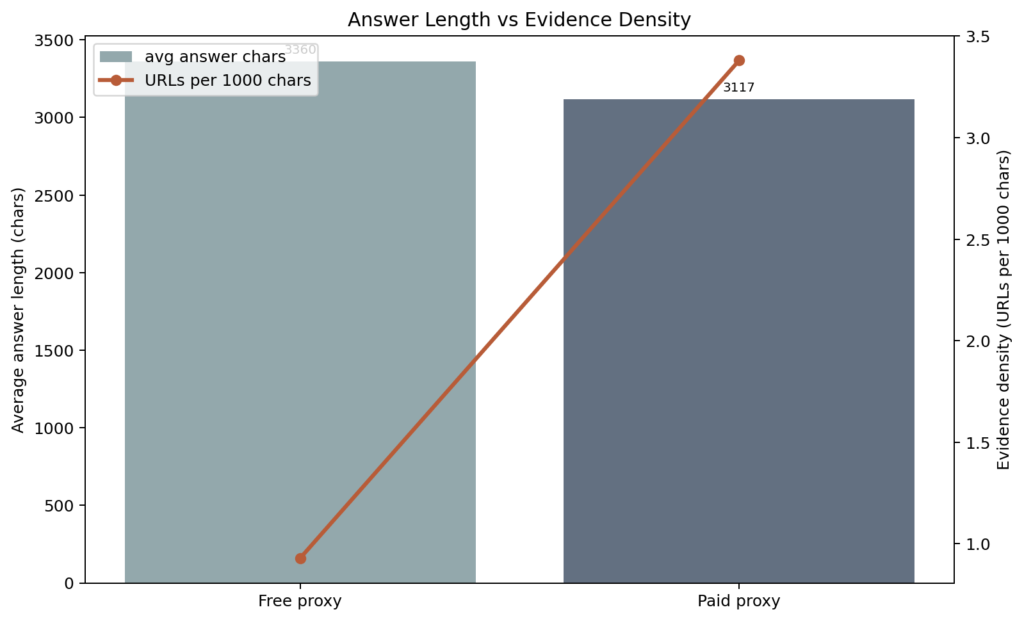
The paid-like group surfaced more sources, more URLs, more citations, and more live web grounding per unit of text. Same fluency. Thinner evidence trail.
Two schemas, two execution patterns
The SSE stream schemas themselves tell the same story, and it is worth looking at them directly.
The free stream schema is comparatively lean. It carries the core message object, content references, citation encoding, URL moderation events, and search markers. The message flow is direct: prompt → (optional search) → answer. What you see in the stream is largely what you get.
The logged-in / paid schema is a different beast. It exposes a richer orchestration layer before the final answer arrives: reasoning status fields, reasoning start and end times, reasoning recap messages, thinking preamble containers, story events, chime version, turn exchange ID, save capability, and additional server-side metadata events. The reasoning phase is visible as a distinct stage, separate from search, separate from answer assembly.


We should not overread internal implementation from observable stream fields. But the structural difference aligns tightly with the behavioural data: the paid-like trace reveals more intermediate state, more deliberation, more evidence assembly before the answer lands.
A model can sound schema-aware while staying weakly grounded. It can mention structured data without validating the live page. It can describe machine-readability without checking whether the site currently provides it.
The gap is not vocabulary. It is execution.
The economics of AI trust
Lily Ray recently described the mechanism in her Substack piece (you can read it here) on the AI Slop Loop:
“Repetition is treated as consensus. If enough sources say it, it becomes fact.”
This is exactly why the free-tier grounding gap matters for marketers. When a model searches less and relies more on parametric memory, it becomes more vulnerable to repeated low-quality claims. Not because it lacks schema vocabulary. Because it does fewer verification steps.
Stale positioning. Wrong product descriptions. Hallucinated capabilities. Competitor-biased summaries from old articles. AI slop that entered the training data and never got corrected. All of it becomes more likely when the evidence trail is thin.
What marketers should do
The answer is not two separate AI visibility strategies, one for free-tier users, one for paid-tier users. That is not how this works, and it is not actionable.
The answer is one trust infrastructure program with two jobs.
Make the entity easy to remember. For memory-led AI experiences, your brand needs a clean, consistent, durable entity footprint. Stable company description. Clear category. Consistent product names. Strong third-party corroboration. Unambiguous sameAs links. If the model answers from memory, the memory needs to be clean and hard to pollute, and how ChatGPT processes named entities helps explain why consistency matters so much.
Make the evidence easy to verify. For search-grounded AI experiences, your site must provide fresh, crawlable, machine-readable evidence. Entity pages. Structured data. XML sitemaps. Product and service documentation. Canonical URLs. Knowledge Graphs. If the model searches, the evidence needs to be easy to find, parse, and cite.
Structured data and Knowledge Graphs do both jobs. They shape what gets remembered and they make live verification easier. That is not an SEO enhancement. It is trust infrastructure.
The new outskirts of the web
Free-tier AI users may encounter answers that look complete, fluent, and confident, but rest on compressed memory rather than current evidence.
That is the new digital divide. Not between people who have access to AI and people who do not. Between people whose AI experience is grounded in live, verifiable evidence and people whose AI experience reflects whatever the model happened to retain.
The future of AI visibility will not be won only by producing more content. It will be won by building a machine-readable evidence layer that works across both modes: memory-led and search-grounded. For a deeper look at where this is heading, see our analysis of OpenAI’s emerging semantic layer.
Make the entity memorable. Make the evidence verifiable.